Information Asymmetries
and
Simultaneous versus Sequential Voting*
Rebecca B. Morton
and
Kenneth C. Williams
Abstract
We theoretically and empirically compare sequential with simultaneous voting elections and the impact of the representativeness of early voters in sequential voting on the electoral outcome when voters have asymmetric information about the candidates. We use a simple three-candidate model where one candidate is a Condorcet winner, i.e. would defeat either opponent in a pairwise competition. However, under complete information multiple equilibria exist in which any of the three candidates could win election. Theoretically, in simultaneous voting elections with voters asymmetrically informed about the candidates, the candidate better known is more likely to win, regardless of whether this candidate is the Condorcet winner or not. In sequential voting, early voters should vote "informatively" and multiple equilibria exist. Using laboratory elections, we investigate our theoretical predictions and consider which of the equilibrium outcomes are more likely. Better known candidates are more likely to win in simultaneous voting, regardless of candidate type. Early voters in sequential voting elections vote informatively and, when given detail on voting by early voters, later voters appear to infer information about the candidates from early voting. The Condorcet winner is more likely to win in sequential voting elections than in simultaneous voting elections when that candidate is less well known. If early voters are not representative of the voting population, there is evidence that their most preferred candidate is more likely to win if they are able to identity their first preference. However, non-representativeness of early voters increases the likelihood that the Condorcet winner will win in sequential voting.
*Rebecca B. Morton is Associate Professor of Political Science at University of Iowa, Iowa City, IA 52242 and Kenneth C. Williams is Associate Professor of Political Science at Michigan State University, East Lansing, MI 48824-1032. This research was funded by the National Science Foundation. We thank Rene Agress and Sara McLaughlin for their invaluable assistance in running the experiments. Earlier versions of this paper were presented at the Arizona State University, the Hoover Institute at Stanford University, the University of Michigan, the University of California, Santa Barbara, the Ohio State University, Princeton University, the University of California, Los Angeles and the 1996 Midwest Political Science Association Meetings. We have also benefited from the helpful comments of Charles Cameron, Cary Covington, Mark Fey, Elisabeth Gerber, and Peverill Squire.
Introduction
Traditional formal theoretical analyses of spatial voting have focused almost exclusively on voting situations where voters make their choices simultaneously. In many cases this is an accurate portrayal and although voting may take place sequentially over a period of time, voters typically make their choices with little knowledge of the choices made by those who have voted earlier. However, there are other notable cases in which groups of voters make choices with knowledge of the choices made by earlier voters in the same election. Roll call voting in legislatures is a type of sequential voting. And in presidential elections in the United States, voters in California and other western states may know when they vote the voting choices cast earlier in the day in eastern states.
A particularly interesting case of sequential voting occurs in United States' presidential primaries. That is, voters in states that have later primaries know the outcomes of the primaries in earlier states when they make their choices. Yet the nomination of the party is a function of the votes in both early and later states. Thus voting that determines the nomination, because of the primary system, occurs sequentially. Sequential voting can take place in a number of other contexts where an electoral outcome is a function of the voting decisions of different groups voting at different times, such as when two houses of a legislative body vote sequentially on legislation or when different countries vote sequentially in referenda over a treaty between the countries.
Whether voting takes place simultaneously or sequentially has recently been the subject of concern for policymakers in the United States in two noteworthy examples. On December 2, 1997 the United States Supreme Court in Foster v. Love declared Louisiana's nonpartisan primary for members of Congress unconstitutional since it resulted in the election of the vast majority (over 80%) of Louisiana members of Congress prior to the uniform election day of the first Tuesday after the first Monday in November as legislated by the United States Congress in 1871. In this ruling the Court noted that the uniform election day was legislated by Congress (first applied to voting in Presidential elections in 1845) to prevent problems that can arise if voting is sequential. In particular, the Congress was concerned that earlier voters may have an undue influence in the outcome of the election and on later voter choices. Justice David Souter wrote in the majority opinion:
" . . . our judgment is buttressed by an appreciation of Congress's object 'to remedy more than one evil arising from the election of members of Congress occurring at different times in the different States.' Ex parte Yarbrough, 110 U. S. 651, 661 (1884). As the sponsor of the original bill put it, Congress was concerned both with the distortion of the voting process threatened when the results of an early federal election in one State can influence later voting in other States, and with the burden on citizens forced to turn out on two different election days to make final selections of federal officers in presidential election years: 'Unless we do fix some time at which, as a rule, Representatives shall be elected, it will be in the power of each State to fix upon a different day, and we may have a canvass going on all over the Union at different times. It gives some States undue advantage. . . . I can remember, in 1840, when the news from Pennsylvania and other States that held their elections prior to the presidential election settled the presidential election as effectually as it was afterward done . . . . I agree . . . that Indiana, Ohio, and Pennsylvania, by voting in October, have an influence. But what I contend is that that it is an undue advantage, that it is a wrong, and that it is a wrong also to the people of those States, that once in four years they shall be put to the trouble of having a double election.' Cong. Globe, 42nd Cong., 2d Sess., 141 (19871) (remarks of Rep. Butler)."
Thus, Justice Souter contends that Congress legislated a uniform election day partly because of concerns that sequential voting would lead to different outcomes than simultaneous voting if states that vote earlier have a greater influence than other states. The argument that states that vote early have an improper sway over the eventual outcome has also been of increasing interest in the presidential primary election system as presidential primaries have become more important in determining candidate nominations. States such as Iowa and New Hampshire have been subject to swelling criticism as the primaries have begun to supercede conventions in choosing party nominations for president. As Niall Palmer, in his careful study of the New Hampshire primary, summarizes (1997, p. xviii):
"Since 1952, New Hampshire's first-in-the-nation primary has become one of the most well-known and notorious landmarks of the presidential election calendar . . . . The size and character of the Granite State has been analyzed by media pundits, while campaign strategists have pored over polling data and pumped thousands of dollars into what became, by the late 1960s, a must-win contest. In its share of media coverage and candidate attention, New Hampshire has come to dwarf larger states with greater delegate yields such as Ohio or New York. . . . In this role, New Hampshire . . . has come increasingly under attack from observers and candidates who question the representative quality of its verdict and resent its alleged influence over other states. As the primary marathon lengthened in the 1970s and 1980s, New Hampshire's perceived influence appeared increasingly out of proportion to its actual delegate yield. Criticism of the primary as anachronistic and perverse found echoes in congressional committee rooms and in the offices of national party organizations. During the 1980s, members of the House of Representatives and of the Democratic National Committee made several attempts to rein in New Hampshire's influence. Individual states also became resentful of their neighbor's high profile, claiming New Hampshire denuded the candidate field and left later states with no real candidate choice. Thus began the phenomenon of 'front-loading' primaries as states moved their dates closer to New Hampshire's limelight."
In 16 of the 24 nomination contests since 1952 New Hampshire voters have selected the eventual nominee, suggesting that early voters' most preferred candidates are more likely to win. Hence, the belief that early states have too much influence has led other states to move their primary election dates closer to the beginning of the primary system and closer together. The front-loading of primaries reached a peak in 1996. Between February 6, 1997 and March 19, 1997 there were 28 caucuses and primaries accounting for almost two-thirds of all Republican national convention delegates. By the middle of March the Republican nomination was settled, earlier than in any other race for the presidential nomination without an incumbent in United States history.
But front-loading makes the voting in presidential primaries closer to simultaneous voting and policymakers have begun to argue that the shortening of the voting process can have a detrimental effect on the outcome by reducing the ability of voters to gain information during the sequential voting process. As William Schneider notes (1997, p. 734):
" . . . the 1996 contest also revealed the downside of front-loading. Candidates had to raise a lot of money early. That favored more-established figures such as Dole. Front-loading kept potentially strong candidates from running. And made it impossible for late starters to get in the race. 'I think we've probably made a mistake by front-loading these primaries,' GOP strategist Roger J. Stone said after last year's New Hampshire primary. 'It meant that good men like Jack Kemp and Colin Powell and Dick Cheney didn't make this race because they thought it was either unwinnable or too difficult.'"
Because of the concerns, early in 1996 the Republican National Committee formed a Task Force to study the scheduling of presidential primaries. Jim Nicholson, chairman of the Task Force and chairman of the Republican National Committee's Rules Committee in making his report noted about the primaries in 1996: "As the primary results from one state shifted the strength of candidates within the field, voters in the states next on the schedule often did not have enough time to thoroughly assess the field of candidates; they didn't have the opportunity to make a well-informed decision . . ." The Task Force recommended a number of changes in the primary system, which were approved by the 1996 Republican convention, that award bonus delegates to states willing to schedule their primary later in the season. These changes were explicitly designed to lengthen the period of time between primaries making the voting less like simultaneous voting.
The examples above illustrate two important questions about the timing of voting in elections:
- Sequential voting may allow later voters to make more informed decisions (and perhaps "better" decisions) than they would in simultaneous voting when there is a large number of potential candidates and voters have incomplete and asymmetric information about the candidates.
- Early voters in sequential voting may have an undue influence on the electoral outcome and this influence may be problematic if the early voters are not representative of the voting population as a whole.
The first concern is the "downside" of simultaneous voting while the second is the "downside" of sequential voting. Are these significant concerns? And if so, which is more serious? Does the advantage of possible information accumulation that might occur in sequential voting overcome the disadvantage of possible unequal influence caused by differences in the preferences in early versus late voters?
Despite the fact that whether voting is sequential or simultaneous and the representativeness of early voters in sequential voting appears to matter substantially to policymakers as the two examples illustrate, there is very little theoretical analysis comparing the voting systems. Assuming perfect information, Sloth (1993) shows that the subgame perfect equilibria of roll-call voting games (in which voters vote one after another) are closely related to sophisticated equilibria of agenda voting games where one voter has control over the agenda (sequence of alternatives) and voters vote simultaneously. But this analysis does not yield much insight to a comparison of the two systems when voters' information about the alternatives is less than perfect.
Closer to our research is the work of Fey 1996 and Witt 1997, who examine sequential voting games in the spirit of recent work in the economics literature on information cascades. The economics literature examines the case where consumers have incomplete information and use inferences based on purchases of other consumers to judge the quality of a product. An information cascade occurs when consumers ignore information they have to follow the lead of others. Fey and Witt show that since sequential voting involves a collective decision, voting cascades are not perfect Bayesian equilibria. Our work is distinct from Fey's and Witt's in that they consider an electoral situation in which voters have identical preferences over the outcomes and only differ in the information they have on the state of the world. In our model we consider the situation where voters differ both in the information they have and their preferences over the outcomes. Dekel and Piccione 1997 also consider sequential voting under binary choices and voters do not have common preferences. They show that the informative symmetric equilibria of the simultaneous voting game are also equilibria in any sequential voting structure in the binary case. In our model we examine voting over three options rather than two; we purposely choose a voting situation where there are multiple equilibria under complete information in order to examine the effect of voting structure on the likelihood of the various equilibria.
Empirical research on the effects of sequence on election outcomes and voter behavior is also sparse. While there exists a large amount of empirical research both quantitative and qualitative of simultaneous voting elections and some sequential voting elections such as presidential primaries, to our knowledge no one has conducted a comprehensive empirical comparison of the two types of elections. The closest to a comparison of the two systems is the study of how changes in the presidential primary structure has affected voting and nominations over time. Such a comparison does suggest that the timing of voting may matter. For example, Rhodes Cook argues that front-loading historically clearly advantages better known candidates (1997, p. 1942): "It is no accident that the last two times that dark horses successfully challenged front-runners for the Democratic nomination were in the 1970s (George McGovern in 1972 and Jimmy Carter in 1976). In that era, the primary season started slowly, and little-known candidates had the time to raise money and momentum after doing well in the early rounds." Historical analyses and studies of early voting have also been conducted in an effort to determine if the representativeness of early voters matters, see Palmer 1997 for a survey of the literature on New Hampshire. And Bartels 1988 presents empirical evidence that momentum can affect voter information levels during presidential primaries. Yet the data points on the types of candidates elected are too few and the number of other factors that have also changed with the system too large to allow for strong empirical conclusions about the effects of these historical changes in the timing of Presidential primaries or the representativeness of early voters has on electoral outcomes and voter behavior.
In this paper we present a theoretical and empirical comparison of simultaneous with sequential voting. We examine the two principal concerns of policymakers about the voting process: 1) Whether sequential voting as in drawn out presidential primaries can lead to more informed, and perhaps different or "better," voter choices than simultaneous voting as in compact and front-loaded presidential primaries and 2) the extent that the representativeness of early voters affects the electoral outcomes and voting behavior in sequential voting. We present a simple model of a three-candidate race and use laboratory elections to examine our theoretical predictions empirically. Our model necessarily simplifies the electoral process substantially both to allow for analytical predictions and to facilitate our experimental investigation. However, we believe that it captures some of the more salient features of sequential and simultaneous voting which concern policymakers and allows us to focus on the effects of these features on electoral outcomes and voting behavior.
Our use of experiments permits us to compare voting systems holding voters' preferences constant and to compare the effects of changes in the preference distributions of early voters upon electoral outcomes and voting behavior in sequential voting. We are also able to control the information voters have about the candidates and the way in which this information is provided. Thus, we are able to compile a rich and large data set (250 elections and 6000 voting decisions) on the effects of these important aspects of simultaneous and sequential voting, data that is not available if we restrict our study to naturally occurring elections. However, we see our experimental work not as a substitute for the study of naturally occurring elections, which include the many factors which we omit in our research, but as complementary to that research, providing additional and unique evidence on the effects of different voting institutions on electoral outcomes and voting behavior controlling some of the more difficult to measure variables in naturally occurring elections such as voter preferences and candidate types. Our research, of course, is only one step in the process of increasing our understanding of the effect of the order of voting on electoral outcomes and voting behavior and, we hope, will lead to more study that examines aspects of voting which we necessarily simplify.
In the next section we present our basic model and experimental design. We discuss how our model and design captures some of the more salient features of simultaneous and sequential voting that concern policymakers as discussed above. In Section III we present our theoretical and experimental results on simultaneous voting and Section IV contains our analysis of sequential voting. Concluding remarks are presented in Section V.
A Three Candidate Voting Model with Incomplete
Information
Basic Assumptions about Voters and Candidates
In our model we assume that simple plurality rule voting takes place with three candidates. We assume that there are three types of voters indexed by: i = 1, 2, 3. We also assume that there are three candidates: x, y, and z. Voter i's utility over candidate j, uij, j = x, y, z, is described in Table 1. That is, type 1 voters most prefer x, their second preference is y, and their third is z; type 2 voters most prefer y, and are indifferent between x and z; and type 3 voters most prefer z, their second choice is y, and their third is x. Furthermore, we assume that the utility each type of voter receives from his or her second preference is equal to a. We assume that a > 1/16.
A voter submits a vote vector, (vx,vy,vz) where vx is the number of votes cast for candidate x, etc. Under our assumption of plurality rule, then, a voter can cast the following vote vectors: (1,0,0), (0,1,0), (0,0,1). Note that we do not allow for abstention in our analysis. Finally, define ni as the proportion of type i voters. We assume that n1 = n2 > n3.
[Table 1 about here]
One way to conceptualize the preferences the voters have for the candidates is that the candidates have positions in an ideological dimension or dimensions and voters' utility over the ideological dimension induces their preference orderings over the candidates. If the positions can be arrayed along a single dimension, then we can think of x and z as candidates with extreme positions (one is perhaps a leftist and the other is a rightist) and y as the moderate candidate in the middle. Voters can be assumed to have single-peaked preferences with ideal points at their most preferred candidates' policy positions. Hence y is the candidate most preferred by the median voter. We should note that, however, when voters have complete information about the candidates' positions, there are equilibria in which x and z are expected to tie for first place with y losing. Therefore, the median voter's most preferred candidate is not the only possible winner. But our analysis is not restricted to this point of view or to a single dimensional issue space. If the election is the nomination of a candidate for a later general election, then voter preferences may reflect voters' subjective expected utility from the general election, incorporating the probabilities that a candidate will win the general election along with the candidate's policy position. The preferences may also reflect non-ideological differences between the candidates that voters care about.
Our simple model focuses on a situation in which there is a single candidate who will defeat any other candidate in a pairwise competition, but is the first preference of only a minority of voters (will not win in a three-way race if all voters voted sincerely for their first preference). Candidate y is this candidate, the "Condorcet" winner [see Condorcet 1785]. That is, supporters of x and z are equal and greater in number than supporters of y. Hence, in a three-way contest, for y to win some voters must vote strategically for their second choice. Relaxing the assumption of equality of the proportion of x and z supporters does not change qualitatively the results that follow as long as n1 and n2 are each greater than n3.
Clearly there are a wide range of different assumptions that we could make about voter preferences over the candidates. We chose our preference configuration because we wanted to focus on the situation where there are significant differences in voter preferences and no candidate has a clear mandate or is the first preference of the majority of the voters even if voters have complete information about the candidates. In complete information simultaneous voting, as discussed below, there are equilibria in which any of the three candidates could win election. Thus our analysis is different from the approach taken by Fey 1996 and Witt 1997 where if voters did have complete information, they would agree on a candidate and complete information voting is straightforward, or as in Dekel and Piccione 1997 where voters may have different preferences, but under complete information there would be a clear winner. Our model is able to explore how the representativeness of early voters' preferences with respect to the voting population may affect the electoral outcome (which candidate wins or equilibria occurs in actuality) and voting behavior of later voters in sequential voting.
Experimental Design
In the laboratory elections we used two payoff configurations, one where a = 0.8 (labeled high a payoff configuration) and the other where a = 0.25 (labeled low a payoff configuration). Table 2 presents the actual payoffs used in the experiments (note that to solve for a we normalize the payoff a subject received from the candidate she preferred least at 0 and the payoff she received from her first preference at 1). All subjects were divided into the three "types," 1, 2, or 3, as described by the cash payoffs they would receive conditional on whether x, y, or z won the election as given in the table. In total there were ten type 1 voters, four type 2 voters, and ten voters type 3 voters in each election. Thus, n1 = n3 = 5/12, n2 = 1/6. Notice that the sum of total voter payoffs or utility: 3all i uij is greater when j = y than when j = x or z. Candidate y, as noted above, would defeat either x or z in a pairwise contest, i.e. is the Condorcet winner.
[Table 2 about here]
We assume that the subjects are risk neutral. Risk aversion is equivalent to an increase in the size of a, while risk seeking is equivalent to a decrease in the size of a. Voters were randomly re-assigned types before each election in order to minimize repeated game effects. Also the types were randomly-reordered before each election. Voters were given full information about the distribution of voter types. However, voters did not know the specific identities of the other voters. We conducted 250 laboratory elections at a large public university, drawing from a subject pool recruited from the population of students attending undergraduate classes. In each laboratory election we used 24 subjects. We conducted 10 sessions of 25 elections with a total of 240 subjects and 6000 individual voting decisions.
When the subjects arrived they were seated and given copies of the instructions for the session. Instructions for Sequential Voting are contained in Appendix B. The instructions were read aloud and questions were answered in public. While the instructions carefully explain the nature of the experiment, they do not suggest to the subjects how they should vote or strategies they should use. We gave the subjects a short true/false quiz on the instructions and then addressed in public areas of the instructions that the quiz demonstrated the subjects did not understand. In general, the results of the quiz show that the subjects did understand the instructions. After the quiz, the subjects were seated at computer terminals in a large classroom. While the subjects were not separated by dividers, the display of the computer program was designed such that the screen could not be read from more than three feet away. The sessions each lasted about 2 hours total, with approximately 45 minutes to one hour of instruction. In a post treatment survey 96% of the subjects reported that they felt they understood the rules of the experiment.
In general the subjects appeared to make very few decisions that can be classified as "errors," suggesting that they understood the nature of the payoff matrix and voting game. Of the 6000 individual voting decisions in our experiments, 2258 decisions were made where the voter was explicitly informed of the identity of his or her least preferred candidate, that is, voters of type 1 were told the identity of candidate z, voters of type 2 either were told the identity of candidates x or z, and voters of type 3 were told the identity of candidate x.. Only 6.82% of these voter decisions (2.57% of all voter choices) could be classified as "errors," i.e. a voter knowingly voting for his or her least preferred candidate. We will discuss voter choices in more detail as we analyze our experimental results.
Equilibrium Concept
We use the voting equilibrium concept for simultaneous voting under incomplete information described in Myerson and Weber (1993). They analyze voting games when voters both have preferences over candidates and expectations about the voting behavior of other voters and the resulting chances of candidates' winning. Voting equilibria exist when voter perceptions of relatively close races are justified by the electoral outcome. When voting is sequential we also restrict ourselves to subgame perfect equilibria (voting choices in the later group of voters that are optimal according to our equilibrium concept within the voting subgame given the outcome of the earlier voting). A voter's vote can affect the election outcome only if two or more candidates are in a tie for first place in the election. How a voter then perceives the relative likelihood of the assorted "close races" should matter in the voter's ballot choice. As in Myerson and Weber, we assume the following:
1. Nearties between two candidates are perceived to be much more likely than between three or more candidates.
2. A voter's perceived probability that a particular ballot changes the outcome of the election between candidates is proportional to the difference in the votes cast for the two candidates. We define pjk as the "pivot" probability that candidates j and k are in a close race for first place. These pivot probabilities are assumed to satisfy the following ordering condition such that with three candidates, j, k, h: if the votes cast for j are less than the votes cast for k, then pjh # epkh, where 0 # e < 1.
3. Voters make ballot choices in order to maximize their expected utility.
Under these assumptions, then, voter i will choose a vote vector which maximizes:
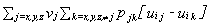
0
Following Myerson and Weber, it can be shown that the pivot probabilities can be rescaled to sum to one and as e goes to zero the rescaled pivot probabilities converge to a limit vector q =(qxy,qxz,qyz) which also sums to one. Note qjk is then the rescaled pivot probability that candidates j and k are in a close race for first place. Myerson and Weber show that qjk > 0 only if one of the following conditions holds (Theorem 2, Myerson and Weber):
1. Either candidates j and k are both in the set of likely winners.
2. Or, either j or k is the unique likely winner and the other candidate has the secondhighest predicted score.
Thus, if candidate j is expected to receive the third highest vote totals or to be the secondhighest vote receiver but the other two candidates are expected to be in a tie, then qjk = 0, all k … j. That is, voters perceive that candidate j has no chance for winning if she or he is not expected to be in first place alone, in a tie for first place, or in second place when there is an expected unique first place winner and will place a zero weight on the utility gained or lost from voting for that candidate as compared to another candidate. Voters will place a positive weight on the utility gained or lost from voting for candidates that are expected to be in first place alone, in a tie for first place, or in second place when there is an expected unique first place winner, since they perceive that their votes may affect the outcome of the election in those cases. Note that assuming that voters place a positive weight on the utility difference for voting for the second place candidate when there is an expected unique first place winner does not necessarily mean that the voters perceive that the relevant pivot probability that these two candidates are in a close race, pjk, is large, the assumption is only that it is positive although it may be extremely small, almost negligible, as pivot probabilities might be in a large presidential primary. Note that while we work with the re-scaled pivot probabilities that sum to one in order to explain the theoretical analysis, this does not mean that we assume that voters perceive these pivot probabilities as large. Our assumption is simply that voters consider which candidates might potentially be in close races for first place in making their voting decisions, knowing that the probability of such a close race might be considerably tiny. Voters vote for the candidate for whom their expected utility gain is highest given their expectations of the outcome. We assume that in equilibrium these expectations are justified.
In our analysis, we will restrict ourselves to symmetric equilibria, that is, equilibria in which identical voters have identical voting strategies. We assume that no voters knowingly vote for their least preferred choices which are at best weakly dominated strategies. Suppose that the voters know the candidates' true positions. Then for voters of type 2, only vote vector (0,1,0) is an undominated strategy, since both candidates 1 and 3 are their least preferred choices. Thus, these voters, if they know the positions of all the candidates, will always vote for candidate y. Similarly, voters of types 1 and 3, if they know the positions of all the candidates, should not vote for their third preferences of candidates z and x, respectively.
The interesting question is when will voters of types 1 and 3 vote strategically for their second choice, candidate y, or their first choices, x and z, respectively? We chose an experimental design in which type 2 voters are in the minority so that we could focus on a situation in which some voters of types 1 and 3 must vote strategically for their second choice for y, the Condorcet winner, to win. We also chose a design in which both groups of types 1 and 3 voters are equal so that one of these groups is not obviously in the majority and thus may seem to have an electoral advantage.
In a complete information voting game under these assumptions of voter preferences equilibria are possible in which y wins (voters of types 1 and/or 3 vote strategically for y) or x and z tie (when types 1 and 3 voters vote sincerely for their first choices). Under complete information, both types of equilibria are possible as long as a > 0. Which equilibrium occurs in actuality is determined by voter expectations. When a type 1 or 3 voter perceives that her most preferred candidate, x or z respectively, is likely to be in last place, it is optimal for her to vote strategically helping y to win and in equilibrium the outcome justifies her expectations. When a type 1 or 3 voter perceives that her most preferred candidate is more or equally likely to be in a close race for first place, she will vote sincerely for her first preference helping her favorite to be in a tie for first place and also justifying her expectations.
While y is the candidate who maximizes the sum of payoffs for the voters and is the Condrocet winner, y does not necessarily win in all equilibria since voter expectations about the electoral outcome and likely close races can result in y losing the election. By choosing this distribution of voter preferences over candidates we can investigate theoretically and empirically how the different voting systems (simultaneous and sequential) affect which equilibrium occurs and how information asymmetries work in an election where there are possible multiple equilibrium outcomes.
Information Assumptions, Simultaneous Voting,
and Sequential Voting
We are particularly interested in the effects of simultaneous versus sequential voting and the representativeness of early voters in sequential voting under incomplete voter information about candidates. As we noted in the Introduction, policymakers argue that when voting is drawn out (sequential), voters are able to make more informed choices about candidates and the electoral outcomes will be different. When voting is compacted (simultaneous), policymakers argue that candidates well known to all voters are advantaged and more likely to win. As Rhodes Cooks concludes about the Democratic primaries currently scheduled for 2000 (p. 1997, p.1942: "The current system is tailor-made for 'someone who is well-known and well-financed and can compete in 35 states in 28 days,' says Mark Siegel, who was executive director of the DNC in the mid-1970s. 'Only one man can do that: Al Gore. This system is really made to order for him.'"
In order to capture the effects of incomplete information in the experiment, candidates were labeled green, orange, or blue in the laboratory elections. Before each election, the candidates were randomly assigned as either x, y or z such that there was a one-to-one correspondence between candidate labels and candidate types. Voters were not told this correspondence. Voters knew then the distribution of candidate types but not the identity of the particular candidates. Before each election, however, voters were told the truthful identity of one of the candidates as described below.
We considered two types of voting processes under our incomplete information setup: simultaneous and sequential voting. We conducted ten sessions in the experiment, two using simultaneous voting (one with high a and the other with low a) and eight using sequential voting (four with high a and four with low a). Thus we conducted 50 simultaneous voting elections and 200 sequential voting elections.
Simultaneous Voting under Incomplete Information. First we analyzed the situation in which voting over the three candidates is simultaneous and all voters are randomly revealed the position of one and only one of the candidates. This situation is designed to represent the case where voting is compact and candidates campaign to all voters at the same time. However, one candidate is better known than the rest of the candidates when the voters vote (like Dole in the Republican primaries in 1996 or as Gore is anticipated to be in the Democratic primaries in 2000). In our experiments we operationalized this in the simultaneous treatments by truthfully revealing to all voters one of the candidates, green, orange, or blue, as either x, y, or z. For example, voters might have been told that orange was actually x. Voters would know that either blue was y and green was z or vice-versa. After one of the candidates was revealed, then all voters voted and payoffs were allocated to voters according to whether candidate x, y, or z won. If the election was a tie, the winner was randomly selected between the tied candidates.
Sequential Voting under Incomplete Information. In the sequential voting treatments, before an election each voter was randomly assigned to an initial voting group, A or B. Each voting group had 12 of the 24 subjects. In these elections first one of the candidates is truthfully randomly revealed as either x, y, or z to voters in group A. Next voters in group A vote. The results of group A's voting is then revealed to all the voters. We revealed this information in two ways. In the "blind" treatment we simply informed group B voters the outcome of group A voting. We conducted four "blind" sequential voting treatments for 100 "blind" sequential voting elections. In the "not blind" treatment group B voters were told how group A voters voted by voter type. We also conducted four "not blind"sequential voting treatments for 100 "not blind" sequential voting elections. After the voting outcome of group A was revealed to voters in group B, a different candidate was truthfully revealed to voters in group B and group B voters voted. Payoffs were again allocated to voters according to whether candidate x, y, or z won with the same tie-breaking procedure if necessary.
The sequential voting treatments are designed to capture important features of sequential voting in actual elections such as presidential primaries. We can think of the early group of voters as voters in a state that has its primary election first such as New Hampshire. These voters are assumed to gain information about the distribution of candidates in the primary during the campaign process, but the information is unequal in the sense that more information is revealed about one candidate than the other two. The later group of voters are then voters in a state that has its primary subsequently after the results of the voting in New Hampshire are publicly known. This later group of voters also are assumed to acquire information about the distribution of candidates during the campaign process in a similar unequal sense, but with more information on a different candidate. Later state voters also have information on the voting in early states, "horse race" information.
Thus voters in group B in the sequential voting treatments receive two types of information: how the early group of voters voted and the specific information they have on one of the candidates. If the voting in the early group of voters reveals the information the early group of voters have acquired, the later group of voters will be fully informed about the true distribution of candidates (i.e. they will know the policy positions of two of the three candidates and therefore be able to infer the position of the third). In the sequential voting treatments, then, the early group of voters use primarily differences between the candidates they learn during the campaign (but they do not have complete information) in making their voting decisions while the later group of votes use both candidate differences they learn during the campaign and "horse race" aspects of previous primaries to infer additional information about the distribution of candidates.
Clearly our choice to reveal to group B voters only horse race information from the voting of group A (rather than the information that group A voters were told) and the identity of a different candidate from that revealed to group A voters (not information specifically about the front-runner in group A) is just one possible way to represent the information process of sequential voting in presidential primaries or other sequential voting elections. We chose to reveal the information in this fashion for the following reasons:
- On Our Assumption That
Later Voters Have Independent Information in Sequential Voting
but that all Voters have Common Information in Simultaneous Voting:
There is evidence that voters in different states voting at different times know different things about the distribution of candidates in presidential primaries. Paolino 1995 finds statistical evidence that voter information levels about various candidates in presidential primaries are a function of their state of residence. Moreover, the nature of sequential voting in presidential primaries implies that it is unreasonable to assume that voters in later states have the same information about candidates as voters in early states as we do in simultaneous voting. That is, as campaigns progress events occur that alter the focus of campaign reporting and campaigns. There is also evidence that later voters know, because of the publicity given early voting, that early voters receive different information about the distribution of candidates than later voters, information that later voters cannot acquire because the campaign process in the states are different. When voting is sequential the campaigning in primaries differs by state. As Palmer discusses, the campaigning in New Hampshire and Iowa is a type of "retail politics" and candidates who use the large-scale approach appropriate in simultaneous voting or as used in later states are actually disadvantaged (1997, p. 53-54): "New Hampshire is as susceptible as any other state in the union to the convenience of wholesale, media-driven politicking, but this campaign technique, which pays dividends in New York or California, is less effective in the Granite State, as the failure of the Forbes media blitz in 1996 demonstrated." Thus, the assumption that in sequential voting the distribution of information across voters by when they vote is different as compared with simultaneous voting is essential for determining whether the two systems as actually used have different effects.
- On Our Assumption
that Later Voters have Horse Race Information about Early Voting:
The media coverage of the voting in early states is primarily focused on horse-race information. For discussions of media concentration on horse race information during presidential primaries see Patterson 1980 and Robinson and Sheehan 1983. As Palmer observes (1997 p. 102):
"Reporters can be too easily drawn into discussions of which candidates are ahead, which are behind, which are moving up or falling back, to the detriment of serious, considered reporting of policy debates. . . . Factors such as advertising revenue, audience totals and changing perspectives on the presentation and development of political stories inevitably affect media approaches to election coverage. The late NBC News' senior political commentator, John Chancellor, regretted the horse race aspects but added in the media's defense that it becomes very difficult for editors and television producers to avoid them in the early caucuses and primaries since so many candidates are in the running."
But the horse race information is not simply who won the early primaries. In sequential voting the media reports more than just which candidate is the front-runner, but the relative size of the candidates' victories. Again, Palmer comments (1997, p. 102): "In presidential primaries, and in New Hampshire above all, victories can be qualified. A first-place finish can prove insufficient, and a close second can sometimes be represented as a moral victory overshadowing the achievement of the winner." Hence, it is not just whether a candidate won or not that is reported, but the size of the victory. The "perceived" winner of a primary is not always the actual winner - Palmer notes that in four out of the twelve Democratic presidential primaries in New Hampshire from 1952 to 1996 the "perceived" winner was different from the actual winner. In our experiments we wanted to determine if voters used the horse race information that is provided about early voting to infer information about the candidates that they did not have. If we had revealed to the later voters the same information that the early voters had we would have been unable to determine how much the later voters used the horse race information in their vote choice.
As noted above we varied the extent that later voters knew the horse race information by voter type; in the not blind treatments voters knew how early voters voted by voter type but in the blind treatments they only knew the overall outcome of the voting. While assuming voters know the breakdown of voting by voter types may seem at first glance unrealistic, many public reports on voting in elections is typically broken down by groups of voters. For example, newspapers and television stories often focus on how blacks or women vote, how union members vote, how votes are distributed by income groups. Thus, we feel it is reasonable to assume that voters do know more than just who won in a voting situation but how different large groups of voters actually voted. In order to test whether the more detailed information was particularly useful for voters, however, we conducted both the blind and not-blind treatments.
The sequential voting treatments also differed in how voter types were distributed across groups. In the "representative" sequential voting treatment, called Sequential 1 (four treatments with 100 sequential voting elections), voter types were equally distributed across voting groups. That is, there were 5 voters of type 1, 2 voters of type 2, and 5 voters of type 3 in each voting group. In the "non-representative" sequential voting treatments, called Sequential 2 (four treatments with 100 sequential voting elections), group A contained all voters of type 1 and half of the voters of type 2 and group B contained all voters of type 3 and half of the voters of type 2. Thus, there were 10 voters of type 1 and 2 voters of type 2 in group A and 2 voters of type 2 and 10 voters of type 3 in group B.
We considered these two different sequential voting treatments in order to test whether differences in ideological preferences across sequential voting groups will affect the information transmission and electoral outcomes that we expect to occur. As noted in the Introduction, the perceived downside of sequential voting is that early voters have an undue influence on the electoral outcome. Palmer contends (1997, p. 48): "Clearly, the question of the representative quality of a New Hampshire primary lies at the heart of the continuing controversy over its elevated electoral status." Much of the movement toward front-loading of primaries has occurred because other states have believed that their states' preferences are not represented by the voters in the early states. Many in the popular media have repeatedly expressed concern that presidential nominations are highly contingent on performance in early states that may not be representative of the nations' voting preferences, i.e. more extremely conservative or liberal. We use the two different treatments to see if preference distributional differences can have an affect on the outcomes.
Voter Strategies and Equilibria under Simultaneous Voting
Theoretical Analysis of Simultaneous Voting With Incomplete Information
With incomplete information about two of the candidates, a strong bias is induced for the candidate who is known with certainty in simultaneous voting. If that candidate is either x or z and her supporters are large enough, her supporters have a dominant strategy to vote for her and the other voters have a dominant strategy to randomize between the other two candidates, regardless of the size of a. Given the size of the revealed candidate's supporters, she is likely to win making voting for her a dominant strategy for her supporters. If the "revealed" candidate is the Condorcet winner, y, all voters have a dominant strategy of voting for her if a > 0.5. If a < 0.5, then only the type 2 voters will vote for y, and the other voters will randomize between the unrevealed candidates. Thus, the revealed candidate is likely to win unless she is y and a < 0.5.
The possible symmetric equilibria under simultaneous voting in our experimental setup are summarized in the following proposition (where j » k means candidates j and k are expected to be in a tie and j >> k means that candidate j is expected to receive more voters than candidate k). Proofs of all propositions are presented in Appendix A.
Proposition 1: When voting is simultaneous and voters know the true position of only one of the three candidates, then the following voting equilibria exist in pure strategies:
i) If x is revealed, x >> z » y
ii) If y is revealed, y >> x » z if a > 0.5, x » z » y if a = 0.5, and x » z >> y if a < 0.5
iii) If z is revealed, z >> y » x
Experimental Results on Simultaneous Voting
Our theoretical analysis predicts that candidates revealed are more likely to win in simultaneous voting in the high a treatment and when either x or z is revealed in the low a treatment. Table 3 presents the data on candidate wins in the two simultaneous treatments. In the high a treatment we find that the candidate revealed never loses outright (24 wins and 1 two-way tie), which is statistically greater than chance. In the low a treatment the probability that the candidate revealed wins is also significantly greater than chance but significantly less than in the high a treatment (16 wins, 5 two-way ties, and 4 losses). While generally supportive of our predictions, the distribution of losses and two-way ties in the low a treatment (3 for candidates x and z) is surprising since our prediction is that y is less likely to win when revealed in the low a treatment, not x and z.
[Table 3 here]
Since the number of elections that we are examining are not large, these differences may merely reflect voter errors committed in early periods idiosyncratic to one of the treatments. Our predictions about candidate wins depend on voters using the following predicted equilibrium strategies:
1. When either x or z is revealed, the voters who most prefer that candidate will vote for that candidate (types 1 and 3 respectively) and the other voters will randomize between the other two candidates.
2. When y is revealed, all voters will vote for y in the high a treatment. In the low a treatment only type 2 voters will vote for y.
Table 4 presents data on the choices made by voters in the simultaneous voting elections. In 90% of the 1200 voting decisions in the two simultaneous treatments the subjects voted as predicted, which is substantially greater than chance. One tendency that subjects may have is to always vote for the candidate revealed, regardless of their expected payoff. Assuming that voters always vote for the revealed candidate explains only 57.46% of the decisions. Yet, if we restrict our analysis to the 10% of unpredicted votes, 82.35% are votes for the revealed candidate when the prediction is that the voter votes for an unrevealed candidate. Thus, unpredicted votes appear to reflect a tendency to vote for a revealed candidate. It is useful to examine whether the deviations from the predicted strategies varied with voter type and/or the size of a. Therefore, we consider the behavior of the different types of voters in the simultaneous voting treatment as compared to the specific predictions.
[Table 4 here]
Types 1 and 3 Voter Decisions in Simultaneous Elections. As predicted, when types 1 and 3 voters are told the identity of their least preferred candidate, they vote for an unrevealed candidate approximately 96% of the time in the high a treatment and 98% of the time in the low a treatment. When they are told the identity of their first preference they vote as predicted for their first preference 100% of the time in the high a treatment and 98% of the time in the low a treatment. When their second preference is revealed, y, they vote as predicted 96% of the time in the high a treatment (voting for y) but only 59% of the time in the low a treatment (voting for x or z). As predicted, the reduction in a significantly reduces the number of types 1 and 3 voters who vote for y, yet there is still a significant percentage of voters who continue to vote for y. This may be a sign that some of the subjects are risk averse in that our predictions depend on the assumption of risk neutrality. Risk aversion would imply a higher value for a voter's second preference for a given a, and a greater willingness to vote for y.
Type 2 Voter Decisions in Simultaneous Elections. In general type 2 voters also vote significantly as predicted. However, there are more deviations from the predicted strategies among the type 2 voters than there are among the types 1 and 3 voters. In the high a treatment type 2 voters display a tendency to vote for the revealed candidate when this is unpredicted (doing so in 20 out of 56 cases = 35.71% of the time) and in the low a treatment type 2 voters display a tendency to vote for an unrevealed candidate when this is unpredicted (7 out of 28 cases = 25% of the time). A reduction in unpredicted votes accompanies the decrease in a, which is a decrease in the payoff to voters from their less preferred alternatives and an increase the cost of voting for the revealed candidate when this is unpredicted.
In conclusion, we find that voters in the simultaneous voting elections vote overall as expected (90% of the decisions). The vast majority of the 10% of unpredicted votes, 82.35%, are votes for a revealed candidate. As predicted, decreasing a does affect voter decisions significantly, types 1 and 3 voters vote less for y when a declines. However, some types 1 and 3 voters (41.43%) appear risk averse and continue to vote for y when y is revealed and a is low. Type 2 voters' errors are also affected by the size of a: when a is high they tend to vote for revealed candidates even when these candidates are not their first choice and when a is low they make less errors. We now turn to our analysis of sequential voting under asymmetric information.
Voter Strategies and Equilibria under Sequential Voting
Theoretical Analysis of Sequential Voting Under Incomplete Information
Information Revelation in Sequential Voting. In our sequential voting treatments voters in group A are truthfully revealed the identity of one of the candidates, vote, and then voters in group B are truthfully revealed the identity of a different candidate and the outcome of the voting in group A by voter type. The first theoretical question to consider is whether voters in group A should vote "informatively," that is, can the voting in group A reveal information to voters in group B? Specifically, will group A voters' voting choices be such that group B voters can, given sufficient information about group A voting, figure out what group A voters have been told (given the information that group B voters are also told)? We find that the answer to the first part of the question is yes, group A voters will vote "informatively."
In order to give an intuitive understanding of this result, we will work through some of the possible cases. Consider for example, the case where x is revealed to group A and z is revealed to group B and a is high. First assume that voting is not informative, that voters in group A use the same voting strategy regardless of which candidate has been revealed to them. Voting by group A is thus expected to be random and unrelated to the information acquired. Voters of type 3 in group B clearly have a weakly dominant or dominant strategy of always voting for z since their expected utility from voting for z is greater than their expected utility from randomizing between x and y. Voters of types 1 and 2 in group B also have a weakly dominant or dominant strategy of randomizing between x and y since their expected utility from randomizing is greater than their expected utility from voting for z. If the voting in group A is random and unrelated to the information that has been revealed to them, then the expected outcome of the election will be z >> y » x with a limit pivot probability vector of (0.5,0.5,0). However, in this case voters of type 1 in group A cannot be maximizing expected utility since their expected utility from voting for x is greater than any randomization scheme involving voting for one of the other candidates also, similarly for voters of type 2 who would have a higher expected utility from randomizing between y and z. Voting randomly in group A would make voters of types 1 and 2 worse off in this case. Hence, uninformative voting always penalizes some voters in group A by advantaging the candidate revealed to voters in group B.
This result is stated formally for all cases in Proposition 2 below.
Proposition 2 Under sequential voting with incomplete information, group A voters will find it expected utility maximizing to vote non-randomly, or "informatively."
Equilibrium Voting Strategies for Group A. Since it is not rational for voters in group A to completely randomize their votes regardless of the candidate revealed to them and vote uninformatively, then voters in group A will vote in order to maximize their expected utility given the information attained. In fact, voters in group A should vote as voters in simultaneous voting elections in which voters know the identity of only one of the three candidates. If either x or z is revealed, the supporters of that candidate will vote for their first preference and the other two types of voters will randomize. If y is revealed all voters in group A will vote for the y if a is high. If a is low then voters of type 2 will vote for y and voters of types 1 and 3 will randomize between x and z. Proposition 3 below states this result formally:
Proposition 3: When voting is sequential, group A voting is informative, and group A voters know the true position of only one of the three candidates, then group A voters will use the following pure strategies:
I) If x is revealed to group A, type 1 voters in group A will vote for x and types 2 and 3 voters will randomize between y and z
ii) If y is revealed to group A, type 2 voters in group A will vote for y. Types 1 and 3 voters in group A will vote for y if a > 0.5; if a = 0.5, they will randomize between all three candidates, and if a < 0.5 they will randomize between x and z.
iii) If z is revealed to group A, type 3 voters in group A will vote for z and types 1 and 2 voters will randomize between y and z
Equilibrium Voting Strategies for Group B. Hence, group A voters will not vote randomly, but informatively, reflecting their preferences. But how "informative" is this voting? That is, since the voting in group A is partly random will group B voters be really able to always infer the information that group A voters have? Consider the example above. In the not blind treatment voters in group B will know the identity of z, that voters in group A know either x or y, and observe that all of type 1 voters have voted for x (5 votes for x) and that the types 2 and 3 voters have voted for either y or z. Thus, they can infer the identity of x. That is, they know that either x or y has been revealed to the group A voters and that if y had been revealed all the voters would have voted for y. In the blind treatment the inference is also possible, but in some cases the randomization of voting may prevent voters in group B from distinguishing whether candidate x or y was revealed to group A. Voters in group B should also have more difficulty distinguishing group A information from group A voting when a is low, since in that case the revelation of y should not lead to all group A members voting for y. While it is still rational for group A voters to vote informatively in these cases (not voting informatively would leave the outcome to the preferences of group B as above), group B voters may not be able in some cases to infer the information that group A voters have. When group B voters cannot infer the information that group A voters have, group B voters will vote as predicted in simultaneous voting given the information that they have been given. This is summarized in Proposition 4 below:
Proposition 4: When voting is sequential and group B voters are unable to infer the information group A voters have (either due to randomization in the voting of group A or because they do not know the voting by voter type), then group B voters will use the following pure strategies:
I) If x is revealed to group B, type 1 voters in group B will vote for x and types 2 and 3 voters will randomize between y and z
ii) If y is revealed to group B, type 2 voters in group B will vote for y. Types 1 and 3 voters in group B will vote for y if a > 0.5; if a = 0.5, they will randomize between all three candidates, and if a < 0.5 they will randomize between x and z.
iii) If z is revealed to group B, type 3 voters in group B will vote for z and types 1 and 2 voters will randomize between y and z
But in some cases group B voters will be able to infer the information that group A voters have by observing group A voting. What are the predicted strategies for voters in group B when they are able to infer the identity of all three candidates? Type 2 voters in group B will always have a weakly dominant or dominant strategy of voting for y, since they prefer y to either x or z and are indifferent between x and z. However, as noted above, types 1 and 3 voters have a choice between voting strategically for y or sincerely for their first preference. Moreover, because of the randomization possible in group A voting, our predictions of group B voting depend on the outcome of group A voting. In some cases only equilibria with some strategic voting by types 1 and 3 voters are predicted and in some cases both types of equilibria are predicted.
In order to provide some intuition concerning the process we will illustrate some examples of the types of equilibria that can occur and the predicted voting in each case. For the examples below we will assume that x has been truthfully revealed to group A and voters in group B are not blind (know the voting in group A by voter type). First we will consider Sequential 1 in which voters of all three types are equally divided between groups A and B. Voters of type 1 in group A are expected to vote for x and x is expected to receive 5 votes from group A. Voters of types 2 and 3, however, are expected to randomize between y and z, therefore the seven votes of these types will be randomly distributed between y and z.
Example 1: Only A Strategic Voting Equilibrium Is Possible. Consider one of the possible vote totals that can occur in group A: y receives all 7 votes from types 2 and 3 voters in group A. In this case only one equilibrium can be supported, y >> x >> z. Voters of type 3 in group B will vote strategically for y since z is expected to have a zero pivot probability of being in a close race for first place with either other candidate. Voters of types 1 and 2 will vote sincerely in group B since they perceive that their first choice has a positive pivot probability of being in a close race for first place.
To better understand why this is the only equilibrium possible in this example, consider some of the alternatives: Suppose voters of type 3 vote sincerely and voters of type 1 vote strategically and the expected outcome is y >> z » x. In this case, voters of type 1 are not rational since there is a positive pivot probability that x is in a close race for first and their expected utility is higher by voting sincerely. Suppose that all voters of group B vote sincerely and the expected outcome is x >> y >> z. In this case, voters of type 3 are not rational since there is a zero pivot probability that z is in a close race for first and their expected utility is higher by voting strategically for y. Finally consider the case where both voters of types 1 and 3 vote strategically. In this case the expected outcome is y >> x >> z and voters of type 1 are not voting rationally since they would gain by voting sincerely.
Example 2: Sincere and Strategic Voting Equilibria Are Possible. Now assume that the randomization is such that y receives 3 votes and z receives 4 votes. In this case a sincere voting equilibrium exists, in which x >> z >> y. Since the race is expected to be between x and z, voters of types 1 and 3 vote sincerely for their first preferences. Notice that in the sincere voting equilibria, x, the candidate revealed to group A is the likely winner. But there are also two strategic voting equilibria: y >> z » x, in which voters of type 1 vote strategically for y and x » y >> z, where voters of type 3 vote strategically for y. In the strategic voting equilibria y is the likely winner. Hence, the sequential nature of the voting process and the randomization of votes can lead to the potential of two possible equilibrium outcomes with either x or y winning. However, if both types 1 and 3 voters vote strategically, the expected outcome is y >> x >> z, in which case voters of type 1 are not voting rationally since they expect their candidate is more likely to be in a close race with y for first place than z, and voting sincerely is expected utility maximizing for type 1 voters in group B.
Other Cases: In all cases when the randomization of votes in group A are such that z receives at least two votes, both sincere and strategic voting equilibria are possible. A similar analysis holds for when the candidate revealed to voters in group A is z. Depending on the vote totals received, both sincere and strategic voting equilibria are possible. Notice that when x or z is revealed to group A the randomization of group A voting determines the type of equilibria possible and the extent that the revealed candidate (x or z) wins or y wins.
What do we expect to happen if the candidate revealed to voters in group A is y? All voters in group A will vote for y and thus we expect either that voters in group B will vote sincerely or types 1 and/or 3 will vote strategically for y while type 2 voters vote sincerely. In this case y is the expected winner in all equilibria with a > 0.5. Thus with high a when y is revealed there are both sincere and strategic voting equilibria but y is the predicted winner in either case. In contrast if a is low, randomization of voting can lead to both wins by all three candidates when y is revealed to group A.
Sequential 1 versus Sequential 2. How do our predictions change when we examine voting in Sequential 2 in which voter preferences are asymmetrically distributed? In Sequential 2 if x is revealed to group A, we expect x to receive 10 votes and the two type 2 voters to randomize between y and z. Again, both sincere and strategic voting equilibria are possible and group B voters of type 3 will either vote sincerely or strategically. The equilibria that occur in this case are either expected ties between x and z, or expected wins by either y or z. If y is revealed and a is high, all voters in group A vote for y and we expect that voters of type 3 in group B will vote sincerely since x will be expected to receive zero votes. The only predicted equilibrium in this case is a sincere voting equilibrium in which y is expected to win and z is expected to receive second place. If z is revealed to voters in group A, both sincere and strategic voting equilibria are possible given the vote totals of the randomization by the voters in group A. If the randomization leads to a large amount of votes for x, outcomes in which x is expected to win or tie for first place are possible. The greater the randomization leads to votes for y, the greater the likelihood of equilibria with z winning through sincere voting by voters in group B or y winning due to strategic voting.
We summarize our predictions of the sequential voting equilibria in Proposition 5:
Proposition 5: When voting is sequential with voters in group A informed of the true position of only one of the three candidates, voters in group B informed of the true position of a different candidate and able to infer from group A voting group A's information, then there are two types of equilibria possible: sincere voting equilibria in which all voters in group B vote sincerely for their first preferences or strategic voting equilibria in which either type 1 and/or type 3 voters in group B vote for y. These equilibria and the electoral outcomes depend upon the potential randomization of voting in group A. When y is revealed to group A and a > 0.5, then in all the equilibria y is the expected winner. When x or z is revealed to group A or y is revealed and a £ 0.5 then multiple equilibria typically exist in which the expected winner varies.
Experimental Analysis of Sequential Voting Under
Incomplete Information: Sequential Voting Versus Simultaneous
Voting
In the Introduction we noted that there are two principal concerns about sequential and simultaneous voting: whether sequential voting allows voters to make more informed choices and whether the representativeness of early voters affects the electoral outcome in sequential voting. We will first consider the extent that sequential voting allows voters to make more informed decisions than in simultaneous voting. The argument that sequential voting allows voters to make more informed choices than in simultaneous voting has two parts: 1) candidates elected under simultaneous and sequential voting are different and 2) later voters in sequential voting gain information through the voting process about the distribution of candidates. We will first consider the extent that the candidates elected under the two systems differ.
Election Winners in Sequential Voting versus Simultaneous Voting. In simultaneous voting elections the assumption is that voters are all exposed to candidates during the same campaign and one candidate is better known to all voters. This candidate is expected to win. We found in the simultaneous voting elections that the revealed candidate was significantly likely to win, however, less so as a was reduced. In sequential voting elections, in contrast, the campaign provides different pieces of information about the candidates to the voters and later voters also know how the earlier voters chose. Thus, theoretically the candidate revealed first or better known to the first voters is not as likely to win as she would if she were the revealed candidate in the simultaneous treatments when that candidate is x or z when a is high and in general when a is low.
Table 5 presents data on the eventual electoral success of candidates revealed to group A in the sequential voting elections. The candidate revealed to group A won significantly more than by chance, 119 of 200 elections or 59.5% of the time and tied for first in 9 elections or 4.5% of the time. But compared to the revealed candidate in the simultaneous voting elections (who won 40 out of the 50 elections, 80% of the time, and tied for first in 6 elections or 12% of the time), the candidate revealed to group A is in general significantly less likely to win [with a mean difference of -0.2425, a standard error of 0.054546 and a t-statistic of -4.44579].
[Table 5 here]
Our analysis above suggests that the ability of the candidate revealed to group A to win is related to the type of candidate revealed. As discussed earlier, if we think of the candidates as aligned in a unidimensional policy space, y is the median voter's preferred candidate or the "moderate" candidate. As the Condorcet winner, y would defeat either x or z in a pairwise competition. Thus, if either x or z is elected, then the voters have chosen a candidate that is preferred less than one of the losers. It is useful then to compare whether the type of voting (simultaneous v. sequential) leads to more or less wins by y.
A simple comparison of electoral success of y in the two election systems shows that while y does win a greater percentage of sequential voting elections (94 wins out of 200 elections, 47%, with 11 ties for first place, 5.5%) than simultaneous elections (19 wins out of 50 elections, 38%, with 3 ties for first place, 6%) the difference is insignificant [mean difference of 0.0875 with a standard error of 0.0762743 and a t-statistic of 1.14718]. Overall, y wins less often when revealed to group A in the sequential elections than when revealed to all voters in the simultaneous elections [there is a mean difference of -0.1522367 in the percentage of wins, with a standard error of 0.0712848 and a t-statistic of -2.13561]. But the ability of y to win should depend on the size of a, when a is high y is the expected winner in both simultaneous and sequential voting but not when a is low. In the sequential high a treatments y was revealed to group A in 40 out of 100 of the elections, winning 36 and tying for first place twice. We cannot compare this statistically to the simultaneous voting elections since in the simultaneous elections y won in 100% of the elections in which y was revealed to all voters. In the sequential low a treatments y was revealed to group A in 37 elections, winning 28 and tying for first place twice. As expected, there is a significant difference in the success rate of y between the high and low a treatments in the sequential voting elections [the mean difference is 0.2763514 with a standard error of 0.0861023 and a t-statisic of 3.20957]. However, the success rate of y in the low a is not significantly different from the percentage of wins when y is revealed to voters in the simultaneous voting elections [the mean difference is 0.2084943 with a standard error of 0.1623682 and a t-statistic of 1.28408]. Thus, the evidence suggests that when y is revealed to group A, the electoral outcome is significantly different from when y is revealed to all voters in simultaneous voting elections when a is high but less so when a is low.
These results seem to suggest that simultaneous voting may advantage y more than sequential voting. But y also wins a number of elections in sequential voting when y is not revealed to group A voters (i.e. is not the first revealed candidate), 35 out of 123 elections (28.46%) tying for first place in 5.69% of the elections. This is significantly more than the success rate of y when x or z were revealed in the simultaneous voting elections [the mean difference is 0.2036331 with a standard error of 0.0634999 and a t-statistic of 3]. When either x or z is revealed to group A that candidate wins 48.33% of the time (29/60) when a is high (with 3/60 ties for first place) and 49.21% of the time (31/63) when a is low (with 2/63 first place ties). There is no statistical difference between these two success rates in sequential voting elections by the value of a, as predicted [the mean difference is 0.0003968 with a standard error of 0.0890364 and a t-statistic of 0.004457]. However, the candidate revealed to A, when either x or z, is statistically less likely to win than when either x or z is revealed to voters in simultaneous elections [the mean difference is -0.3043699 with a standard error of 0.0732636 and a t-statistic of -4.15445]. Thus, x and z win significantly less often when revealed to group A voters in the sequential voting elections than when revealed to all voters in the simultaneous voting elections.
These combined results suggest that y may be more likely to win in sequential voting than in simultaneous voting. While instructive, with the simple analysis it is difficult to control for the combined effects of other variables on the likelihood that y wins such as the size of a, whether group B voters were blind to the distribution of voting in group A by voting type, the election period (if "learning" by the subjects takes place during the experiment this may either increase or decrease the likelihood of y winning), whether the early voters are representative of the electorate (as in sequential 1) or not (as in sequential 2), and whether y is revealed to group B voters. Table 6 reports results of a logit estimating the log likelihood of y winning as a function of these variables as well as whether the voting was simultaneous or sequential.
[Table 6 here]
The null case in the logit is a simultaneous voting election with x or z revealed and a high. The logit analysis shows that y does win significantly more in the sequential voting elections than in simultaneous voting elections. The coefficient on SEQUENTIAL VOTING is significantly positive. The higher value of a and later periods increase the probability that y wins but not as significantly (the coefficient on LOW a is negative and the coefficient on PERIOD is positive). Revealing y to both simultaneous (Y REVEALED TO SIMULTANEOUS VOTERS) and group A sequential voters (Y REVEALED TO GROUP A SEQUENTIAL VOTERS) increases the likelihood that y wins (Y REVEALED TO GROUP B SEQUENTIAL VOTERS has a positive effect, but is insignificant). However, if B voters are blind (BLIND IN SEQUENTIAL), y is significantly less likely to win. The odds ratio for y winning when a is high in a sequential voting election where B voters are blind versus a simultaneous voting election is 1.595602, whereas the odds ratio for y winning with a is high in a sequential voting election where B voters are not blind versus a simultaneous voting election is 3.725053. When a is low, the odds ratio for y winning in a sequential voting election where B voters are blind versus a simultaneous voting election is 0.8772739, whereas the odds ratio for y winning with a is low in a sequential voting election where B voters are blind versus a simultaneous voting election is 2.048063. Thus, when a is high y is still more likely to win even if B voters do not have detailed information about A voting, but when a is low, y is less likely to win when B voters do not have detailed information.
Our analysis also suggests that whether sequential or simultaneous voting benefits the electoral success of y depends on the distribution of information about the candidates in the two systems. If y is the candidate most likely to be well known in simultaneous voting, then y is more likely to win in that electoral system than in sequential voting where y is known by group A voters (the odds ratio in the first case is 86.8861 versus the odds ratio in the second is 39.76238). It is possible that the sequential voting process can lead to a win by x or z depending upon the sequence in which information is provided about the candidates. That is, in sequential voting even when some voters know the identity of y, because the campaign is not one in which information about candidates is shared simultaneously, y can lose when y would win in a simultaneous voting situation. Yet, if y is not the candidate most well known in simultaneous voting, then sequential voting is more likely to lead to an electoral success for y whether y is revealed to the sequential voters or not and even when the group B voters do not have detailed information about voting in group A by voter type if a is high.
Group A Individual Voting Decisions. The second proposed advantage of sequential voting over simultaneous voting is the supposition that later voters become more informed than they otherwise would by observing the choices of earlier voters. For this to occur the voters in group A would need to vote "informatively," voting as voters in the simultaneous voting treatment, as discussed above. 87.08% of the 2400 voting decisions in group A are as predicted for "informative" voting. This percentage is large, but it is significantly less than the percentage of predicted votes in the simultaneous voting elections [the mean difference between the two equals -.0291667, with a standard error of 0.0110431, and a t statistic of -2.64117]. As in the simultaneous voting elections voters have a tendency to vote for the candidate revealed, 53.88% of the time. Of the unpredicted votes in the sequential voting elections, 66.77% were votes for the revealed candidate when this is unpredicted, which is less than in the simultaneous voting elections.
Table 7 presents more detailed data on the extent that voters in group A vote informatively. As in the simultaneous voting elections, voters generally vote for their first preference if revealed. As a decreases, voters of types 1 and 3 vote less for y when y is revealed (84% decreases to 62.97%). Type 2 voters, as in the simultaneous elections, have a tendency to vote for revealed candidates even when unpredicted in the high a treatment, but less so in the low a treatment.
[Table 7 here]
Group B Individual Voting Decisions. The results above support the contention that voters in group A vote informatively. However, do voters in group B use the results from group A in their voting decisions and, if so, how? As discussed above, if voters in group B do not use the results from group A as an information source they should vote as voters in the simultaneous voting elections with respect to the candidate revealed to them. 81.25% of the 2400 voting decisions are consistent with the predicted voting decisions assuming the group B voters do not use the results of group A voting. Table 8 presents detailed data on group B voting decisions with respect to the candidate revealed to group B.
[Table 8 here]
But it would be premature to conclude from this analysis that group B voters do not use group A voting to infer information about the candidates. Many of these voting choices are also consistent with equilibria in which voters in group B choose with complete information, using the outcome of group A voting. Specifically, type 2 voters' choices under complete information will be consistent with their choices assuming they do not use the results of group A voting. And types 1 and 3 voters should, under complete information, never vote for their third preference which is consistent with the prediction if these voters ignored group A voting and their third preference is revealed. Finally, as noted above, equilibria exist in which types 1 and 3 group B voters may vote sincerely for their first preference or strategically for their second and in all but one of the elections both of these equilibria are possible, depending on the outcome of group A voting. Hence, distinguishing when voter behavior in group B is influenced by group A voting is difficult.
Evidence that voters in group B may be using the information from group A voting exists if group B voters vote unpredictably for their second or first preference. That is, if group B voters vote significantly for their first preference when their second preference is revealed to them or if group B voters vote significantly for their second preference when their first preference is revealed to them, then group B voters may be using the results of group A voting in making their choices since otherwise they should choose randomly. Examination of the voting choices of types 1 and 3 voters does suggest that these voters may be so influenced. When their first preference is revealed to them, they do not vote for that candidate 24.78% of the time which is significantly greater than the percentage observed of group A types 1 and 3 voters (7.04%) or types 1 and 3 voters in the simultaneous voting elections (0%). 80.72% (67/83) of these "unpredicted" votes are for candidate y, suggesting that these voters use the outcome of voting in group A to infer y's identity and chose to vote for y instead of their first preference even though their first preference was revealed to them.
In the high a treatment there are also a significant percentage of types 1 and 3 voters in group B not voting for their second preference when revealed to them, 47.58% of the time, which is greater than 16% of the same voters in group A voters and 4.09% of the same voters in the simultaneous voting elections. 75.80% (119/157) of these votes are for the voters' first preference instead which suggests that the voters are using the results of group A voting to infer the identity of their first preference. However, when a is low, these voters vote more for their second preference when revealed to them as compared to the voters in group A and in the simultaneous voting elections. Moreover, all of the unpredicted votes in this case are actually for the voters' third preferences suggesting that in the low a treatment these voters were not able to use the results of group A voting effectively. These results suggest that in the high a treatment group B voters do to some extent use group A voting to infer the identity of particular candidates, but less so when a is low.
A more precise way to determine whether group B voting is influenced by group A voting is to examine the extent that group B voters vote for their least preferred candidate (suggesting that they do not know the identity of all the candidates) as compared with voters in group A and in the simultaneous voting elections. If voters gain information through the sequential voting process, then these votes for a voter's least preferred candidate should be significantly less in group B voting than in the simultaneous voting elections and in group A voting in the sequential voting elections. But there are many factors that can affect voters' tendencies to vote for their least preferred candidates. There may be some "learning" and voting in later periods may reflect that. We have seen that as election periods increase, y is more likely to win. As a is decreased, voting in group A is more random and harder to determine. Voters in group B's abilities to infer information from group A voting may be affected by the candidate revealed to them and their own voter types. That is, if a group B voter's least preferred candidate is revealed to group B then that voter is less likely to vote for him or her regardless of information available from group A voting. Thus, an analysis of the voting in group B should control for these factors. In order to determine whether these factors influenced the extent that voters voted for their least preferred candidate we report a logit explaining the decision to vote for a voter's least preferred candidate by voter type in Table 9.
[Table 9 here]
We combine the data for all voters in all treatments in the estimation. The dependent variable in these logits is coded 1 if a voter voter for her least preferred candidate (a vote for z for a voter of type 1, a vote for x or z for a voter of type 2, and a vote for x for a voter of type 3) and 0 otherwise. The variable PERIOD measures the election period (1-24), the other independent variables are self-explanatory dummy variables which are coded 1 or 0 accordingly as explained in the Table. The variable most relevant for our concerns is GROUP B VOTER. It is negative and significant, which shows that group B voters are less likely to vote for their least preferred candidate. GROUP B VOTER BLIND measures the effect when group B voters are not told the outcome of A voting by voter type. It is significantly positive, showing that when group B voters are given less detailed information they are less able to infer the identities of the candidates and more likely to vote for their least preferred candidate.
The other variables in the analysis have generally predictable signs and significance levels. That is, PERIOD is significantly negative showing that voters tend to vote less for their least preferred candidate in later periods than in earlier ones. Voters vote less for their least preference when y is revealed (reflecting the fact that for none of the voters is y a voter's least preferred candidate). LOW a is significantly positive. Type 2 voters are significantly more likely to vote for their least preference, but less so when y is revealed.
In summary, our experimental results provide evidence that:
- First revealed candidates are less likely to win in sequential voting than in simultaneous voting.
- y is more likely to win in simultaneous voting when y is revealed, but more likely to win in sequential voting when y's identity is less well known.
- Group A voters in sequential voting generally vote informatively.
- Group B voters, when a is high and they know voting outcomes by voter type, do infer information from group A voting about the information that group A voters are given and vote less often for their least preferred candidate than voters in simultaneous voting elections or early voters in sequential voting elections.
Our results suggest that sequential voting can allow later voters to make informed decisions but that this depends crucially on the detail of the information they have about early voting and the relative value the type 1 and 3 voters place on their second preference, y. Recall that both BLIND and LOW a significantly decrease the probability that y wins. These results combined with our analysis of group B voters suggest that the ability of group B voters to infer information about group A voting is closely related to the probability that y wins. If later voters have detailed information about group A voting and place a high relative value on their second preferences (specifically types 1 and 3 voters have a high relative value for y), then sequential voting is more likely to lead to more informed voting by later voters and, as a consequence, more wins for y.
Experimental Analysis of Sequential Voting Under Incomplete Information: Representativeness of Early Voters and Sequential Voting Outcomes
Sequential 2 Versus Sequential 1. As noted, the downside of sequential voting is the potential undue influence weighed by unrepresentative early voters. In Sequential 1 voter types are distributed equally across the two voter groups while in Sequential 2 voters are unequally distributed. A comparison of means test shows that there is no significant difference in the percentages of wins by first candidates revealed in the two treatments. But this evidence is misleading since some of the experimental results discussed above suggest that early voters can influence electoral outcomes. We have seen that the candidate revealed to early voters is more likely to win than chance. Thus, rather than comparing candidate wins by candidate revealed in general, the relevant comparison is whether there are differences in the advantage given to candidates revealed first to group A voters according to the representativeness of the early voters. In our experimental design the majority of the early voters prefer candidate x. If they have an undue influence and they know the identity of x, then perhaps x is more likely to win (and theoretically this is when x is most likely to win).
Table 10 presents comparison of means tests for the number of wins by candidates revealed to group A in Sequential 2 elections versus Sequential 1 elections by candidate type. x wins significantly more when revealed to group A voters in Sequential 2 than Sequential 1 and y and z both win significantly less when revealed to group A voters in Sequential 2 than Sequential 1. Thus, when group A voters are told the identity of their first preference, that candidate is more likely to win and the representativeness of group A voters appears to matter.
[Table 10 here]
Yet the conclusion that the early voters have an undue influence should be qualified. When z is revealed to group B (the first preference of the majority of group B voters in Sequential 2) z is much more likely to win with a t-statistic of 2.3545. Hence, the advantage of group A voters in Sequential 2 crucially depends on whether they can identify which candidate is their first preference and the information that group B voters have. When group A voters can identify their first preference, x, and group B voters are not told the identity of their first preference, z, (i.e. x is revealed to A and y is revealed to B which occurred in 20 elections in Sequential 2 and 16 elections in Sequential 1), x is much more likely to win in Sequential 2 with a t-statistic of 3.9793.
In order to control for the possible combined effects of the variables in the analysi, we report logit estimates of the probability that x wins in Table 11. We find that a dummy variable for Sequential 2 elections, SEQUENTIAL 2, has an unpredicted insignificant negative sign. However, a dummy variable for x revealed to group A, x REVEALED TO GROUP A, is significantly positive and interacted with the dummy variable SEQUENTIAL 2 is significantly positive. A dummy variable for z revealed to group A, z REVEALED TO GROUP A, is also significantly positive. Other variables (BLIND, PERIOD, LOW a) are insignificant but have predictable signs (positive, negative, and positive, respectively). If we estimate a logit restricting our analysis to the cases where x was revealed to group A voters (63 observations), then the odds ratio that sequential 2 voting elections leads to more wins by x than sequential 1 is 9.040818. If B voters are blind, the odds that x is more likely to win in sequential 2 voting elections increase to 36.81214. However, in a logit restricted to cases where x is not revealed to group A voters (137 observations), then the odds ratio that sequential 2 voting elections leads to more wins by x than in sequential 1 is 0.6400534 and only increases to 0.6637849 when B voters are blind. Thus, x wins more often when early voters are less representative only when x is revealed to them.
[Table 11 here]
Sequential 2 versus Simultaneous Voting Elections. Our analysis shows that it is possible that non-representative early voters can lead to a bias in the electoral outcomes in sequential voting when these voters know which of the three candidates they most prefer. However, our analysis also shows that sequential voting in general compared to simultaneous voting can in some circumstances (when a is high y is revealed to group A voters and not the well known candidate in simultaneous voting) lead to more wins by y, the Condorcet winner. Does this advantage of sequential voting outweigh the disadvantage when early voters in sequential voting are nonrepresentative? In order to answer this question, we estimated logits similar to that reported in Table 6, which separate the comparisons with simultaneous voting by sequential voting election type. The results of these estimations are presented in Table 12. We find very similar results to those reported in Table 6 for Sequential 2 (however BLIND and LOW a are no longer significant). We find that when a is low and B voters are blind, y is more likely to win in Sequential 2 voting elections than in simultaneous voting elections; the odds ratio is 2.598025. Yet, when the opposite comparison is made (Sequential 1 versus simultaneous voting elections) the odds ratio that y wins more is extremely low, 0.2367398. In the Sequential 1 comparison logit, the dummy variable for a sequential voting election (SEQUENTIAL VOTING) is insignificant. And in Sequential 1 voting elections blind B voters lead to less wins by win as compared to simultaneous voting elections even when a is high (the odds ratio is 0.4344855) whereas in Sequential 2 y is still more likely to win (the odds ratio is 4.436287). Hence, when early voters in sequential voting are nonrepresentative, sequential voting's advantage over simultaneous voting is greater rather than less.
[Table 12 here]
Conclusions
The extent that voting is sequential or simultaneous in elections has been the subject of a recent United States Supreme Court decision and a longstanding concern in presidential primaries for the last 20 years. Policymakers have argued for simultaneous voting in federal elections and in presidential primaries in order to prevent early voters from having a perceived undue influence on electoral outcomes. Conversely, other policymakers have contended that sequential voting, as in presidential primaries, allows voters to make more informed decisions and advantages candidates less well known to all voters. In this paper we consider these two issues theoretically and using laboratory experiments.
We find that the representativeness of early voters in sequential voting can significantly affect the electoral outcomes. When early voters are not representative of the electorate at large and can identify their most preferred candidate, that candidate has a greater likelihood of winning. If they can identify a candidate that is their least preferred or less preferred, that candidate has a lower likelihood of winning. Moreover, when these voters can identify their most preferred candidate and later voters have less explicit information on candidates the early voters' most preferred candidates are more likely to win. When voter information is asymmetrically distributed across voters, the representativeness of early voters can affect the electoral outcome.
We also find evidence that in sequential voting later voters can use horse race information from early voting to infer information about candidates and thus make voting choices that more reflect their preferences. That is, later voters in the sequential voting elections vote less often for their least preferred candidate than voters in simultaneous elections or early voters in sequential voting elections when a is high (voters relative value of their second preference is high) and later voters know the outcome of early voting by voter type. However, when a is low (voters relative value of their second preference is low) or voters are not given information about the early voting by voter type, later voters appear less able to infer information about the candidates from the electoral outcomes of the early voting. Thus, if there is the possibility that a candidate has a high relative value as a second preference to a large majority of voters, then information aggregation in sequential voting is more likely. Information aggregation can occur in sequential voting, but this depends on the detail of the information provided to voters.
Finally, when later voters are able to use early voting information and y would not be the well-known candidate in simultaneous voting, y is more likely to win in sequential than in simultaneous voting elections. Since y is the Condorcet winner and thus is preferred by a majority of the voters to either x or z in pairwise competitions, sequential voting, under some conditions, produces more desirable electoral outcomes than simultaneous voting if it is likely that the well-known candidate in simultaneous voting may not be the Condorcet winner. Moreover, when early voters are non-representative of the voting population the advantage of sequential voting over simultaneous voting is greater and less affected by the value the voters place on the Condorcet winner and the detail of information that voters have.
Our results indicate that where there is the possibility that one unknown candidate will receive a high relative value as a second preference for a large number of voters (is a Condorcet winner), sequential voting may allow voters to aggregate information about the distribution of candidates types through the electoral process and lead to a higher probability of that candidate winning than in simultaneous voting. Sequential voting may, in this context, lead to the election of a Condorcet winner who might lose in simultaneous voting elections in which he or she is relatively unknown. Thus, policymakers who contend that sequential voting in presidential primaries has an informational advantage are supported if the later voters are given sufficient information about the outcome of voting in early states and the Condorcet winner or winners are unknown. Representativeness of early voters is most likely to be a concern in sequential voting in presidential primaries and other contexts when early voters know well their most preferred candidates and later voters are less able to identify the candidates (have less of their own independent information), but non-representativeness increases the advantage of sequential over simultaneous voting when the potential Condorcet winner is not well known offsetting the possible negative consequences.
Appendix A: Proofs of Propositions
Proof of Propositions 1 and 4: For the purposes of the proof, assume that orange's position is really x, blue's position is y, green's position is z, and a > 0.5. Assume that orange's position is revealed as x. In this case voters of type 1 have a dominant strategy of always voting for orange and voters of types 2 and 3 have a dominant strategy of always voting for any combination of green and blue. Only one possible symmetric voting equilibrium in pure strategies exists, i.e. with x ‡ y » z. The limit pivot probability vector that supports this equilibrium is (q12 ,q13 ,q23) = (0.5,0.5,0). Assume that blue's position is revealed as y. In this case voters of all types have either a weakly dominant or dominant strategy of always voting for blue, y is the expected winner and z and x are expected to be tied for second place. Assume that green's position is revealed as z. In this case voters of type 3 have the same options as voters of type 1 when orange's position is revealed. If a £ 0.5 the analysis follows if x or z are revealed. If y is revealed and a < 0.5 types 1 and 3 maximize expected utility by voting for an unrevealed candidate and if a = 0.5, these voters should randomize in the two strategies (they will be indifferent).
QED
Proof of Proposition 2: First assume that voting is not informative, that voters in group A use the same voting strategy regardless of which candidate has been revealed to them. Voting by group A is thus expected to be random and unrelated to the information acquired. Consider the possible cases. Assume that the candidate revealed to voters in group A is x, the candidate revealed to voters in group B is z, and a > 0.5. Voters of type 1 in group A cannot be rational by randomizing their votes in this case since z will be the expected winner and x will be expected to be tied for second. Similarly, if z is revealed to voters in group A and x is revealed to voters in group B, voters of type 3 cannot be maximizing expected utility if they vote unrelated to their information since x will be the expected winner and z will be expected to be tied for second. Now suppose that y is revealed to voters in group A and z is revealed to voters in group B. Again, voting in group B will advantage z with y expected to be tied for second, which means that randomized voting in group A by both voters of types 1 and 2 would not be expected utility maximizing. Similarly if y is revealed to voters in group A and x is revealed to voters in group B, randomized voting by voters of types 2 and 3 is not expected utility maximizing since x will be advantaged and more likely to win with y expected to be tied for second. Finally, assume that x is revealed to voters in group A and y is revealed to voters in group B. Voters of type 1 in group A are not expected utility maximizing by not voting for x since x will be expected to be in a tie for second and similar results hold if z is revealed to voters in group A and y is revealed to voters in group B. The results when a £ 0.5 straightforwardly follow.
QED
Proof of Proposition 3: Assume that x is revealed to voters in group A. They expect that group B voters will know the entire distribution of candidates. Since type 2 voters always have a dominant or weakly dominant strategy of voting for y regardless of the expected outcome of the election, votes of type 2 will find it rational to randomize between y and z. Type 3 voters have a weakly dominant or dominant strategy of voting for either y or z, depending on which of these two candidates are more likely to be in second place or tied for first in the election. Given that this is just as likely for either and that voting for candidate x is dominated for voters of type 3, voters of type 3 will also randomize between y and z. Finally, type 1 voters receive a higher expected utility from voting for x than taking the chance of the lottery between y and z. A similar analysis holds for when z is revealed to voters in group A. When y is revealed, again type 2 voters will vote for y since this is their weakly dominant or dominant strategy regardless of outcome. Both voters of types 1 and 3 also have a weakly dominant or dominant strategy of voting for y rather than taking the lottery between x and z since a > 0.5. QED
Proof of Proposition 5: Assume that x is revealed to group A. Type 1 voters of group A vote for x and types 2 and 3 randomize between y and z. Sincere voting equilibria are possible if the randomization from the votes in group A is such that sincere voting and the outcome of voting in group A leads to an expected outcome with either x and z in a tie for first place or one of the extremist is the expected winner and the other is expected to be in second place alone. Strategic voting equilibria are possible when voters of type 3 vote strategically for y and the randomization from the votes in group A is such that the expected outcome is either a tie between x and y or one is expected to be in first place and the other is expected to be in second place alone. Strategic voting equilibria are also possible in which voters of type 1 vote strategically for y and the randomization from the votes in group A is such that the expected outcome is either a tie between z and y or one is expected to be in first place and the other is expected to be in second place alone. Strategic voting equilibria are not possible in which both types 1 and 3 voters vote for y in group B, since if either x or z is expected to be in second place alone, that candidate's supporters maximize expected utility by voting sincerely and if both extreme candidates are expected to be in a tie for second place, both candidates' supporters maximize expected utility by voting sincerely. Converse results hold if z is revealed to group A. If y is revealed to group A, then y is the expected winner in any equilibrium, and voting by group B members depends on expectations of which candidate will be in second place. If one extremist candidate is expected to be in second place alone, that candidate's supporters maximize expected utility by voting sincerely and the other extremist candidate's supporters maximize expected utility by voting strategically. If both extremists are expected to be in a tie for second place, both extremist supporters maximize expected utility by voting sincerely.
QED
Appendix B: Instructions and Screen Display
General: This is an experiment that examines voting behavior. The instructions are simple and if you are careful, and make good decisions you can earn a considerable amount of money. Your payoff depends on your decisions, but also on the decisions that other subjects make, and chance.
During the experiment you will participate in a series of elections. As in other elections, there will be voters who cast ballots for competing candidates. In the experiment you will play the role of voters. You will participate in a series of plurality elections. Plurality elections are elections in which there are more than two competing candidates. In this experiment there will be three candidates -- we will call them Orange, Blue, and Green. The winner in a plurality election is simply the candidate who receives the most votes. In the case where candidates receive an equal share of the votes, the winner will be selected by a random draw. Your payoff in the experiment is tied directly to the winning candidate. Each of you will be given a payoff schedule that assigns a monetary amount to each of the three candidates. You will receive the monetary amount associated with the winning candidate.
Payoffs: Since you are here primarily for the money involved, let me explain your payoffs in more detail now. Each of you will have a payoff schedule that associates a monetary amount with each of the three candidates. For example, to you, the Orange candidate might be worth one dollar, while the Blue candidate might be worth 50 cents and the Green candidate might be worth 25 cents. In this case, the Orange candidate yields the higher payoff. However, for some voters the monetary amounts associated with each candidate might differ. Hence, the Orange candidate might yield a higher payoff for some voters, while the blue candidate might yield a higher payoff for other voters. It is also possible for two or more candidates to be associated with the same payoff. Again, your payoff is based on the monetary amount assigned to the winning candidate. Assume that the monetary amounts associated with the Orange candidate is one dollar and the monetary amount associated with the Green candidate is 50 cents. Consequently, even though the monetary amount associated with the Orange candidate is one dollar, if the Green candidate wins you will only receive 50 cents for that election, regardless of whether you voted for the Green or Orange candidate.
In the experiment each of you will be assigned to one of three voter types. A voter type simply specifies for each voter the monetary amount associated with each candidate. Consider the following payoff schedule. (Note: this is just an example, not the actual payoffs you will see during the experiment.)
|
Orange
|
Blue
|
Green
|
# of voters
|
Type 1
|
1.00
|
.50
|
.25
|
8
|
Type 2
|
.25
|
.50
|
1.00
|
5
|
Type 3
|
1.00
|
.50
|
.50
|
4
|
In this case, if you are assigned to be a type 1 voter, the Orange candidate yields a higher payoff than the Blue candidate, and the Blue candidate yields a higher payoff than the Green Candidate. If you are assigned to be a type 2 voter then the Green candidate yields a higher payoff than the Blue candidate, and the Blue candidate yields a higher payoff than the Orange candidate. And if you are assigned to be a type 3 voter, the Orange candidate yields a higher payoff than the Blue and Green candidates, who each have identical payoffs. During the experiment, you will know your type, but you will not know which subjects have been assigned to the other types. However, you will know the number of voters that have been assigned to a particular type. This number is displayed in the fifth column above. In this example there are eight type 1 voters, five type 2 voters and four type 3 voters.
Using the example above, if we were to hold an election which candidate would win? The candidate that receives the most votes. That is, suppose all voters vote for candidate Green, then Green would receive 17 votes and win. Alternatively, if Green receives 6 votes, Orange receives 7 votes, and Blue receives 3 votes, Orange would be the winner. Suppose that Blue and Orange both receive 6 votes and Green receive 5 votes? Then the computer will randomly choose who is the winner between Blue and Orange.
Again, let me summarize the events thus far. Each of you will be assigned to one of three voter types. You will know your type, and number of voters within the three type categories. Your type determines the monetary amounts associated with each of the three candidates. An election will be held and you will be required to vote for one of the three candidates. You will receive the monetary amount associated with the winning candidate.
Voting Groups: First, we will divide each of you into two groups. One group will be called group A, and the other will be called group B. You will know your assigned group, but you will not know the group other subjects have been assigned to. However, you will know the number of voters assigned within each group. The reason we have divided you into two groups is because you will be voting Sequentially. First, all members of group A will vote for the candidates. The results of the election will be revealed to voters in both groups, then group B voters will vote. In effect we will have two elections, one where group A votes and a second where group B votes. However, the winning candidate will be determined by tallying the votes across the two elections. Consider the new payoff schedule below. This is the same payoff schedule we used above, but now voters have been divided into two groups (the last two columns.) In group A there are eight voters and in group B there are nine. Also notice that within group A, four voters have type 1 preferences, three voters have type 2 preferences and one voter has a type 3 preference.
|
Orange
|
Blue
|
Green
|
# of voters
|
Group A
|
Group B
|
Type 1
|
1.00
|
.50
|
.25
|
8
|
4
|
4
|
Type 2
|
.25
|
.50
|
1.00
|
5
|
3
|
2
|
Type 3
|
1.00
|
.50
|
.50
|
4
|
1
|
3
|
Now let us consider how election results are computed again. Consider the first stage, where only group A voters cast a ballot. There are 8 voters in group A. Suppose all group A voters vote for Green; i.e., Green receives 8 votes from group A, and Blue and Orange receive 0 votes from group A. But Green is not necessarily the winner in the election. The winner will depend also on how group B votes. There are 9 voters in group B. Suppose that all nine voters vote for Blue. Then Blue would be the winner, receiving 9 votes to Green's 8.
Here is a more complicated example: Suppose group A votes as follows: Orange receives 3 votes, Blue 2, and Green 3. Then suppose group B votes as follows: Orange receives 3 votes, Blue 5, and Green 1. Of the 17 total votes, then, Orange has received 6, Blue has received 7, and Green has received 4. Because Blue has received the most votes across both groups, Blue is the winner even though Blue received the least votes in group A. What matters is which candidate receives the most votes from the total across the two groups. Suppose that two of the candidates are tied in total votes across both groups. Then, the computer will randomly choose who is the winner between the two tied candidates.
Information about the Candidates: The second complication is the most important. In the payoff schedule above you knew how each of the three candidates associated with your respective payoff. That is, if you were a type 1 voter, you knew the Orange candidate was worth one dollar, the Blue candidate was worth 50 cents, and the Green candidate was worth 25 cents. In this experiment you will not be given this information. During the experiment you will be voting for either the Orange, Blue or Green candidates, however you will not know which candidate is associated with which payoff. Instead you will see the following payoff schedule (note that as opposed to previous payoff schedules this payoff schedule has different monetary amounts, and the number of voters has been altered).
Payoff Matrix
|
x
|
y
|
z
|
# of voters
|
Group A
|
Group B
|
Type 1
|
1.00
|
.50
|
.25
|
12
|
6
|
6
|
Type 2
|
.25
|
.50
|
1.00
|
12
|
6
|
6
|
Type 3
|
.25
|
1.00
|
.50
|
12
|
6
|
6
|
The Orange candidate could either be type x, y, or z. Similarly, the Green and Blue candidates could either be type x, y, or z. You may wonder at this point how you may figure out which candidate is associate with which payoff (or type). First, before each election, voters in group A will be told the identity of one candidate. They will be told, for example, that the Orange candidate is either type x, y, or x. Hence, group A's problem is to determine the identity of the remaining two candidates. Note that you will participate in several rounds of this experiment, and in each round the computer will randomly reveal the identity of one candidate. So for example in one round it might be the Green candidate is z, and in the next it might be that the Orange candidate is y, or any possible combination. Also note that Candidate identities and types are mutually exclusive. Candidate will never be assigned the same type. That is, if the Green Candidate is z, and the Blue candidate is x, then it must be the case that the Orange candidate is y. Thus, there will never be a case, for example, where the Green and Blue candidate are both assigned to type y.
After group A has made their voting decision, the results will be revealed in the two history boxes (some hypothetical numbers have been inserted for group A):
Election Results by Type
|
Type 1
|
Type 2
|
Type 3
|
|
O
|
B
|
G
|
O
|
B
|
G
|
O
|
B
|
G
|
Group A
|
0
|
3
|
3
|
6
|
0
|
0
|
2
|
2
|
2
|
Group B
| | | |
| | | |
| |
Total
| | | |
| | | |
| |
Election Results by Group
|
O
|
B
|
G
|
Group A
|
8
|
5
|
5
|
Group B
| | | |
Total
| | | |
The first history box is just the voting results broken down by types. The next history box breaks the voting results down by groups. Notice, in the first history box, type 1 voters in group A split between the Blue and Green candidate. Type 2 voters in Group A all voted for the Orange candidate, and type 3 voters were evenly split among the three candidates. This information is aggregated in the second history box. Notice in the first stage the Orange candidate has a three vote lead.
After this information is displayed, it is group B's turn to vote. Prior to casting a ballot, voters within Group B will be told the identity of another candidate. This will be a different candidate than the one revealed to group A. The computer will randomly reveal the identity of one of the two remaining candidates. Again the task for group B is to determine which candidate is associated with what type. Before Group B votes, information about the voting results of group A will be revealed in the history box.
After group B casts their ballots, the votes from both elections will be tallied and the winning candidate will be announced. In the case of a tie between candidates, the computer program randomly selects a winner. Your display will reveal the following information. (Group B's votes have been assigned arbitrarily.) Your display will also reveal the winning candidate and your payoff (a hypothetical payoff is included below).
Election Results by Type
| |
Type
|
1
| |
Type
|
2
| |
Type
|
3
|
|
O
|
B
|
G
|
O
|
B
|
G
|
O
|
B
|
G
|
Group A
|
0
|
3
|
3
|
6
|
0
|
0
|
2
|
2
|
2
|
Group B
|
2
|
2
|
2
|
2
|
2
|
2
|
2
|
2
|
2
|
Total
|
2
|
5
|
5
|
8
|
2
|
2
|
4
|
4
|
4
|
Election Results by Group
|
O
|
B
|
G
|
Group A
|
8
|
5
|
5
|
Group B
|
6
|
6
|
6
|
Total
|
14
|
11
|
11
|
THE WINNING CANDIDATE IS 'O'; YOU RECEIVE A PAYOFF OF 25 CENTS.
After the final results have been announced, your payoff for that period will be recorded in a running tally ( this will be displayed on your computer screen.) We will then repeat this process for an undetermined number of periods. You will not be told how many elections we will have. After completion of the experiment, your payoffs will be tallied, and you will be paid in cash your accumulated earnings. Note that we will play several rounds of this experiment. In each round you will be randomly assigned to either group A or group B, and you will be randomly assigned to one of the three voter types.
Let me summarize the sequence of events; 1.) You will be randomly assigned to either Group A or Group B; 2.) You will be randomly assigned to one of the three voter types; 3.) Group A will be told the identity of one candidate; 4.) Group A will be asked to vote for one of the three candidates; 5.) After group A votes, the results will be revealed in a history box; 6.) Group B will be told the identity of one of the remaining two unknown candidates; 7.) Group B will be asked to vote for one of the three candidates; 8.) The totals from the two elections will be tallied; 9.) a winner is announced and you receive a payoff from the winning candidate; 10.) Repeat the process at #1.
Notes
References
Banerjee, Abhijit V. 1992. "A Simple Model of Herd Behavior." Quarterly Journal of Economics 107(August)797-818.
Bartels, Larry M. 1988. Presidential Primaries and the Dynamics of Public Choice. Princeton, N.J.: Princeton University Press.
Bikhchandani, Sushil, David Hirshleifer, and Ivo Welch. 1992. "A Theory of Fads, Fashions, Custom, and Cultural Change as Information Cascades." Journal of Political Economy 100(October):992-1026.
Brady, Henry E.. 1996. "Strategy, and Momentum in Presidential Primaries." In Political Analysis, Volume 5, ed. John R. Freeman. Ann Arbor: The University of Michigan Press.
Condorcet, M.J.A.N.C., Marquis de, 1785, Essai sur l'Application de l'Analyse la Probabilit des Decisions Rendues la Pluralit des Voix, l'Imprimerie Royale, Paris.
Cook, Rhodes. 1997. "CQ Roundtable: GOP Wants a Revamp of Primary Process." Congressional Quarterly, August 9:1942.
Cooper, Alexandra, and Michael C. Munger. 1996. "The (Un)Predictability of Presidential Primaries with many Candidates: Some Simulation Evidence." Presented at the annual meetings of the American Political Science Association, San Francisco.
Dekel, Eddie and Michele Piccione. 1997. "The Equivalence of Simultaneous and Sequential Binary Elections." working paper, Department of Economics, Northwestern University.
Fey, Mark. 1996. "Informational Cascades, Sequential Elections, and Presidential Primaries." paper presented at the annual meeting of the American Political Science Association in San Francisco, CA.
Filer, John, Kenny, Lawrence, and Rebecca Morton. 1993. "Redistribution, Income, and Voting," American Journal of Political Science, 37 (February): 63-87
Myerson, Roger B. and Robert J. Weber, 1993, "A Theory of Voting Equilibria." American Political Science Review 87(March):102114.
Palmer, Niall 1997. The New Hampshire Primary and the American Electoral Process. Wesport, Connecticut: Praeger.
Paolino, Philip. 1996. "Perceptions of Candidate Viability: Media Effects During the Presidential Nomination Process," Presented at the annual meetings of the American Political Science Association, San Francisco.
Patterson, Thomas E. 1980. The Mass Media Election: How Americans choose their President. New York: Praeger.
Robinson, Michael J., and Margaret Sheehan. 1983. Over the Wire and on TV: CBS and UPI in Campaign 80. New York: Russell Sage Foundation.
Roth, Alvin. 1995. "Introduction to Experimental Economics." in The Handbook of ExperimentalEconomics, ed. by John Kagel and Alvin Roth, Princeton: Princeton University Press.
Schneider, William. 1997. "And Now the GOP is Rewriting its Rules." National Journal. April 12: 734.
Sloth, B. 1993. "The Theory of Voting and Equilibria in non-Cooperative Games." Games and Economic Behavior 5(1):152-169.
Witt, J. 1997. "Herding Behavior in a Roll-Call Voting Game." working paper, Department of Economics, University of Amsterdam.
Table 1: Voter Utility Matrix (Candidate Policy Positions)
Voter Types
|
x
|
y
|
z
|
1
|
1
|
a
|
0
|
2
|
a
|
1
|
a
|
3
|
0
|
a
|
1
|
Table 2: Voter Payoff Matrix in Experiment
| Low a Treatment
| |
Voter
Types
|
x
|
y
|
z
|
Number
of voters
|
1
|
$1.30
|
$0.55
|
$0.30
|
10
|
2
|
$0.55
|
$1.30
|
$0.55
|
4
|
3
|
$0.30
|
$0.55
|
$1.30
|
10
|
| High a Treatment
| |
1
|
$1.10
|
$0.90
|
$0.15
|
10
|
2
|
$0.90
|
$1.10
|
$0.90
|
4
|
3
|
$0.10
|
$0.90
|
$1.10
|
10
|
Table 3: Percentage of Wins by Revealed Candidates in Simultaneous Elections
(Number of Observations in Parentheses)
|
Candidate Revealed in High a Treatment
|
Candidate Revealed in Low a Treatment
|
Electoral Success
|
x or z
|
y
|
x or z
|
y
|
Losses of revealed candidate
|
0
(0/14)
|
0
(0/11)
|
16.67%
(3/18)
|
14.29%
(1/7)
|
two-way ties for revealed candidate
|
7.14%
(1/14)
|
0
(0/11)
|
27.78%
(5/18)
|
0
(0/7)
|
Wins of revealed candidate
|
92.86%
(13/14)
|
100%
(11/11)
|
55.56%
(10/18)
|
85.71%
(6/7)
|
Ties by y when x or z is revealed
|
7.14%
(1/14)
| |
11.11%
(2/18)*
| |
Wins by y when x or z is revealed
|
0%
(0/0)
| |
11.11%
(2/18)*
| |
*Note that some ties and losses involved an unrevealed candidate other than y which is why these numbers differs from the number of two-way ties and wins involving the revealed candidate.
Table 4: Voting Choices in Simultaneous Voting Elections
(Numbers of Observations in parentheses)
|
High a Treatment
|
Low a Treatment
|
Predicted Strategies of
Types 1 & 3 Voters
|
Predicted Vote
|
Unpredicted Vote
|
Predicted Vote
|
Unpredicted Vote
|
3rd Pref. Revealed;
Predicted Strategy:
Random 1st and
2nd preference
|
96.43%
(135/140)
|
3.57%
(5/140)
|
97.78%
(176/180)
|
2.22%
(4/180)
|
2nd Pref. Revealed; Predicted Strategy: 2nd Pref. if a high, randomize if a low
|
95.9%
(211/220)
|
4.09%
(9/220)
|
58.57%
(82/140)
|
41.43%
(58/140)
|
1st Pref. Revealed;
Predicted Strategy:
1st Pref.
|
100%
(140/140)
|
0%
(0/140)
|
97.78%
(176/180)
|
2.22%
(4/180)
|
Predicted Strategies
of Type 2 Voters
|
Predicted
Vote
|
Unpredicted
Vote
|
Predicted
Vote
|
Unpredicted
Vote
|
1st Pref. revealed;
Predicted Strategy:
Vote Revealed Candidate
|
97.73%
(43/44)
|
2.27%
(1/44)
|
75%
(21/28)
|
25%
(7/28)
|
x or z revealed;
Predicted Strategy:
Vote for Unrevealed
|
64.29%
(36/56)
|
35.71%
(20/56)
|
83.33%
(60/72)
|
16.67%
(12/72)
|
Table 5: Percentage of Wins by Candidates Revealed to Group A in Sequential Voting Elections
(Number of Observations in Parentheses)
|
Candidate Revealed to
Group A in High a Treatment
|
Candidate Revealed to
Group A in Low a Treatment
|
Electoral Success
|
x or z
|
y
|
x or z
|
y
|
Losses of revealed candidate
|
46.67%
(28/60)
|
5%
(2/40)
|
47.62%
(30/63)
|
32.43%
(12/37)
|
two-way ties for revealed candidate
|
5%
(3/60)
|
5%
(2/40)
|
3.17%
(2/63)
|
5.41%
(2/37)
|
Wins by revealed candidate
|
48.33%
(29/60)
|
90%
(36/40)
|
49.21%
(31/63)
|
62.16%
(23/37)
|
Ties by y when x or z is revealed
|
6.67%
(4/60)*
| |
4.76%
(3/63)*
| |
Wins by y when x or z is revealed
|
30%
(18/60)*
| |
26.98%
(17/63)*
| |
*Note that some ties and losses involved an unrevealed
candidate other than y which is why these numbers differs from
the number of two-way ties and wins involving the revealed candidate.
Table 6: Electoral Success of Candidate y Logit (Sequentials 1 and 2 versus Simultaneous Voting)
(Null case is x or z revealed in a simultaneous voting election and a high, ties are coded as 0.5).
|
Coefficient
|
Standard Error
|
z
|
p > |z|
|
SEQUENTIAL VOTING
(0 for simultaneous voting, 1 for sequential voting - in baseline sequential voting y is unrevealed)
|
1.315081
|
0.5960283
|
2.206
|
0.027
|
PERIOD
(1-25)
|
0.0404525
|
0.0218608
|
1.850
|
0.064
|
LOW a
(0 for high a, 1 for low a)
|
-0.5981869
|
0.3127951
|
-1.912
|
0.056
|
Y REVEALED TO SIMULTANEOUS VOTERS
(1 for y revealed to simultaneous voters, 0 otherwise)
|
4.464598
|
1.145933
|
3.896
|
0.000
|
Y REVEALED TO GROUP A SEQUENTIAL VOTERS
(1 for y revealed to group A voters in sequential voting, 0 otherwise)
|
2.36784
|
0.4268749
|
5.547
|
0.000
|
Y REVEALED TO GROUP B SEQUENTIAL VOTERS
(1 for y revealed to group B voters in sequential voting, 0 otherwise)
|
0.1766138
|
0.3976743
|
0.444
|
0.657
|
BLIND IN SEQUENTIAL
(1 for blind group B voters in sequential voting, 0 otherwise)
|
-0.8478303
|
0.3344851
|
-2.535
|
0.011
|
CONSTANT
|
-1.90214
|
0.5906736
|
-3.220
|
0.001
|
NUMBER OF OBSERVATIONS
|
250
| | | |
LOG OF LIKELIHOOD FUNCTION
|
-126.21246
| | | |
PSEUDO R2
|
0.2715
| | | |
PERCENT CORRECTLY CLASSIFIED
|
75.20%
| | | |
Table 7: Group A Voting Choices in Sequential Voting Elections
(Numbers of Observations in parentheses)
|
High a Treatment
|
Low a Treatment
|
Predicted Strategies of
Types 1 & 3 Voters
|
Predicted Vote
|
Unpredicted Vote
|
Predicted Vote
|
Unpredicted Vote
|
3rd Pref. Revealed;
Predicted Strategy:
Random 1st and
2nd preference
|
96%
(317/330)
|
4%
(13/330)
|
98.39%
(305/310)
|
1.61%
(5/310)
|
2nd Pref. Revealed; Predicted Strategy: 2nd Pref. if a high, randomize if a low
|
84%
(336/400)
|
16%
(64/400)
|
62.97%
(233/370)
|
37.03%
(137/370)
|
1st Pref. Revealed;
Predicted Strategy:
1st Pref.
|
92.96%
(251/270)
|
7.04%
(19/270)
|
95.63%
(306/320)
|
4.38%
(14/320)
|
Predicted Strategies of Type 2 Voters
|
Predicted
Vote
|
Unpredicted
Vote
|
Predicted
Vote
|
Unpredicted
Vote
|
1st Pref. revealed;
Predicted Strategy:
Vote Revealed Candidate
|
98.75%
(79/80)
|
1.25%
(1/80)
|
91.89%
(68/74)
|
8.11%
(6/74)
|
x or z revealed;
Predicted Strategy:
Vote for Unrevealed
|
72.5%
(87/120)
|
27.5%
(33/120)
|
85.71%
(108/126)
|
14.29%
(18/126)
|
Table 8: Group B Voting Choices in Sequential Voting Elections Ignoring Group A Voting
(Numbers of Observations in parentheses)
|
High a Treatment
|
Low a Treatment
|
Predicted Strategies of
Types 1 & 3 Voters
|
Predicted Vote
|
Unpredicted Vote
|
Predicted Vote
|
Unpredicted Vote
|
3rd Pref. Revealed;
Predicted Strategy:
Random 1st and
2nd preference
|
97.61%
(327/335)
|
2.39%
(8/335)
|
96.71%
(353/365)
|
3.29%
(12/365)
|
2nd Pref. Revealed; Predicted Strategy: 2nd Pref. if a high, randomize if a low
|
52.42%
(173/330)
|
47.58%
(157/330)
|
71.25%
(228/320)
|
28.75%
(92/320)
|
1st Pref. Revealed;
Predicted Strategy:
1st Pref.
|
75.22%
(252/335)
|
24.78%
(83/335)
|
82.54%
(260/315)
|
17.46%
(55/315)
|
Predicted Strategies of Type 2 Voters
|
Predicted
Vote
|
Unpredicted
Vote
|
Predicted
Vote
|
Unpredicted
Vote
|
1st Pref. revealed;
Predicted Strategy:
Vote Revealed Candidate
|
81.82%
(54/66)
|
18.18%
(12/66)
|
89.06%
(57/64)
|
10.94%
(7/64)
|
x or z revealed;
Predicted Strategy:
Vote for Unrevealed
|
93.28%
(125/134)
|
6.72%
(9/134)
|
88.97%
(121/136)
|
11.03%
(15/136)
|
Table 9: Voting for Least Preferred Candidate Logit
(Null case is voting in Group A or simultaneous voting election with a high and y unrevealed)
|
Coefficient
|
Standard Error
|
z
|
p > |z|
|
GROUP B VOTER
(1 for voter in group B in sequential voting, 0 for otherwise)
|
-0.3876172
|
0.1227102
|
-3.159
|
0.002
|
GROUP B VOTER BLIND
(1 for "blind" voter in group B in sequential voting, 0 for otherwise)
|
0.6854003
|
0.1431266
|
4.789
|
0.000
|
PERIOD
(1-25)
|
-0.0237077
|
0.0060486
|
-3.920
|
0.000
|
LOW a*
(0 for high a, 1 for low a)
|
0.6422017
|
0.0889313
|
7.221
|
0.000
|
VOTER TYPE 2
(1 for voter of type 2, 0 otherwise)
|
3.607906
|
0.1335268
|
27.020
|
0.000
|
Y REVEALED TO VOTER
(1 for y directly revealed to the voter, either in simultaneous voting or in the voter's group in sequential voting, 0 otherwise)
|
1.999201
|
0.1233246
|
16.211
|
0.000
|
VOTER TYPE2 * Y REVEALED TO VOTER
(1 for voter type 2 and y revealed to voter, 0 otherwise)
|
-4.292976
|
0.2345029
|
-18.307
|
0.000
|
CONSTANT
|
-3.59841
|
0.1444928
|
-24.904
|
0.000
|
NUMBER OF OBSERVATIONS
|
6000
| | | |
LOG OF LIKELIHOOD FUNCTION
|
-1753.2496
| | | |
PSEUDO R2
|
0.2297
| | | |
PERCENT CORRECTLY CLASSIFIED
|
87.50%
| | | |
*We also estimated a model with BVOTER interacted with LOW a, but the interactive term was insignificant.
Table 10: Comparison of Means Tests of the Percentage of Wins by Candidates Revealed to Group A in Sequential 2 versus Sequential 1 by Candidate Type. Ties are coded as 0.5.
|
x Revealed to Group A
|
y Revealed to Group A
|
z Revealed to Group A
|
Observations in Sequential 2
|
33
|
38
|
29
|
Observations in Sequential 1
|
30
|
39
|
31
|
Mean Difference
(Seq. 2 - Seq. 1)
|
0.3106061
|
-0.1612686
|
-0.4332592
|
Std. Error
|
0.1040192
|
0.0882549
|
0.0931733
|
t statistic
|
2.98605
|
-1.8273
|
-4.65004
|
Table 11: Electoral Success of Candidate x in Sequential Voting
Elections Logit
(Null case is y revealed to Group A, Sequential 1, and a high.)*
|
Coefficient
|
Standard Error
|
z
|
p > |z|
|
BLIND
(1 for "blind" voters in group B, 0 for otherwise)
|
0.4844337
|
0.4332235
|
1.118
|
0.263
|
PERIOD
(1-25)
|
-0.024272
|
0.028872
|
-0.841
|
0.401
|
LOW a
(0 for high a, 1 for low a)
|
0.5740471
|
0.435637
|
1.318
|
0.188
|
SEQUENTIAL 2
(1 for voter sequential 2, 0 for sequential 1)
|
-0.5561003
|
0.5694209
|
-0.977
|
0.329
|
x REVEALED TO GROUP A
(1 for x revealed to group A, 0 otherwise)
|
4.60765
|
1.103578
|
4.175
|
0.000
|
x REVEALED TO GROUP A*SEQUENTIAL 2
(1 for x revealed to Group A and sequential voting, 0 otherwise)
|
2.511676
|
.9238844
|
2.719
|
0.007
|
z REVEALED TO GROUP a
(1 for z revealed to group A, 0 otherwise)
|
3.409132
|
1.051473
|
3.242
|
0.001
|
CONSTANT
|
-4.375803
|
1.14818
|
-3.811
|
0.000
|
NUMBER OF OBSERVATIONS
|
200
| | | |
LOG OF LIKELIHOOD FUNCTION
|
-69.151614
| | | |
PSEUDO R2
|
0.4548
| | | |
PERCENT CORRECTLY CLASSIFIED
|
83.50%
| | | |
*We also estimated models with variables reflecting candidates revealed to group B and additional interactive terms. These terms were insignificant.
Table 12: Electoral Success of Candidate y Logit (by Sequential Voting Election Type)
(Null case is x or z revealed in a simultaneous voting election and a high, ties are coded as 0.5).
|
Sequential 2 versus Simultaneous
|
Sequential 1 versus Simultaneous
|
|
Coefficient
|
Standard Error
|
Coefficient
|
Standard Error
|
SEQUENTIAL VOTING
(0 for simultaneous voting, 1 for sequential 2 or 1 voting - in baseline sequential voting y is unrevealed)
|
1.799752
|
0.6693548
|
0.864991
|
0.75244
|
PERIOD
(1-25)
|
0.0084069
|
0.0274821
|
0.084796
|
0.0355365
|
LOW a
(0 for high a, 1 for low a)
|
-0.5350663
|
0.3964395
|
-0.6072008
|
0.4762249
|
Y REVEALED TO SIMULTANEOUS VOTERS
(1 for y revealed to simultaneous voters, 0 otherwise)
|
4.465915
|
1.142052
|
4.607373
|
1.172957
|
Y REVEALED TO GROUP A SEQUENTIAL VOTERS
(1 for y revealed to group A voters in sequential voting, 0 otherwise)
|
1.198096
|
0.5497937
|
1.253865
|
0.7896784
|
Y REVEALED TO GROUP B SEQUENTIAL VOTERS
(1 for y revealed to group B voters in sequential voting, 0 otherwise)
|
-0.7776236
|
0.5409049
|
1.253865
|
0.67031
|
BLIND IN SEQUENTIAL
(1 for blind group B voters in sequential voting, 0 otherwise)
|
-0.3099346
|
0.4407993
|
-1.698584
|
0.5808174
|
CONSTANT
|
-1.514286
|
0.6292634
|
-2.521669
|
0.7532582
|
NUMBER OF OBSERVATIONS
|
150
| |
150
| |
LOG OF LIKELIHOOD FUNCTION
|
-77.801225
| |
-58.531897
| |
PSEUDO R2
|
0.2517
| |
0.4370
| |
PERCENT CORRECTLY CLASSIFIED
|
72.00%
| |
82.67%
| |