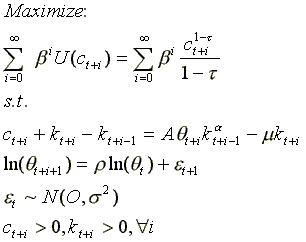 (1)
(1)
This paper compares three approximation methods for solving and simulating real business cycle models: linear quadratic (including log-linear quadratic) methods, the method of parameterized expectations, and the genetic algorithm. Linear quadratic (LQ), log-linear quadratic (log-LQ) and parameterized expectations (PE) methods are commonly used in numerical approximation and simulation of wide classes of real business cycle models. This papers examines what differences the genetic algorithm (GA) may turn up, as the volatility of the stochastic shocks and the relative risk parameter increase in value. Our results show that the GA either closely matches or outperforms the LQ, loq-LQ and PE for approximating an exact solution. For higher degrees of nonlinearity and stochastic volatility, the GA gives slightly different results than the LQ and PE methods. Our results suggest that the GA should at least compliment these approaches for approximating such models.
I. Introduction
This paper compares three approximation methods for solving and simulating real business cycle models: linear quadratic (including log-linear quadratic) methods, the method of parameterized expectations, and the genetic algorithm. Linear quadratic (LQ), log-linear quadratic (log-LQ) and parameterized expectations (PE) methods are commonly used in numerical approximation and simulation of wide classes of real business cycle models. These methods are relatively quick and easy to implement. While other computationally more intensive methods are also used, such as the quadrature-based methods described by Tauchen and Hussey (1991), there has been little application of the genetic algorithm.
The main drawback of the LQ and PE methods is that they are based on continuities and first-order conditions. More often than not, however, there are inequality constraints in macroeconomic models. Consumption and the capital stock, for example, cannot be negative, hours worked usually have an upper limit, and the familiar cash-in-advance constraint may be binding or slack. Furthermore, nonlinear estimation methods crucially depend on starting coefficient values, and thus may become trapped in local optima, or may fail to converge.
The genetic algorithm is not based on continuities or first-order conditions. The inequality constraints are taken seriously. The solution is based on a evolutionary search process over a very wide set of initial values for the parameters which maximize the utility or objective function. The drawback, of course, is that the genetic algorithm is computationally more time consuming.
The purpose of this paper is to show that the GA may give different results than LQ, log LQ, and PE approximation methods, especially when the degree of non-linearity and the volatility of the disturbance terms increase. While the computation time may prevent the GA from taking the place of LQ and PE methods, our results suggest that researches working with relatively noisy or highly nonlinear models should at least check some of the results of LQ and PE solutions with the GA method.
This paper is inspired by the recent work of Den Haan and Marcet (1994), who compared the accuracy of the LQ, log LQ and PE methods for the real growth model analyzed by Taylor and Uhlig (1990) and for the real business cycle model with money due to Cooley and Hansen (1989). In this paper, Den Haan and Marcet propose a test for accuracy based on the sum of squares of the first derivative of the utility function, with solutions based on the LQ, log LQ and PE methods. In their study, the PE method was used with a second-order polynomial. They found that the LQ methods broke down under a relatively high variance for the disturbance term.
The next section is a description of the GA method, for solving
the growth model analyzed by Marcet. We also present a brief
summary of the PE method. Section III is a summary of our simulation
results. The last section concludes.
Consider the following real business cycle model:
(1)
It can be shown that equation system (1) has a closed form analytical
solution only when t=m=1. In this case, the optimal path for
c and k are given by the following system:
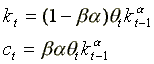 (1')
(1')
Otherwise, approximation methods are needed to solve for the optimal path for given stochastic shocks.
One solution, of course, is to use a linear or log-linear approximation. Following Hansen and Sargent (1991), one can represent the above system as the following state-space model:
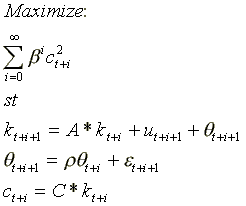 (2)
(2)
where c and k can be written as the levels or the logarithms of consumption and the capital stock, and A* and C* are appropriately chosen for given values of m, and u represents the control variable. The advantage of LQ or log LQ approximation is that solutions can be found quickly, which have the property of certainty equivalence: the parameters yielding the optimal path for the accumulation of capital are independent of the distribution of the random shocks e.
Of course the LQ approximation methods short cut non-linearities either in the objective function or in the constraints. For this reason, Marcet proposed the method of parameterized expectations.
Marcet's method takes seriously the Euler equation for the
stochastic model, with m=1:
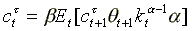 (3)
(3)
The PE method proceeds in the following three steps: first, substitute the conditional expectation on the right-hand side of equation three by a parameterized function
y(g; kt-1,qt), in order to obtain:
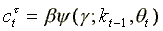 (4)
(4)
Secondly, create a long series of {c,k} with equation (3) and (4); third, run a non-linear regression:
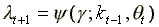 (5)
(5)
and fourth, iterate until g coincides with the result of the non-linear regression.
A common way to parameterize equation (4) is to use the following
log-linear specification:
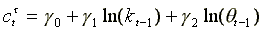 (6)
(6)
The genetic algorithm attempts to solve optimization problems,
whether static or dynamic, using the methods of evolution, specifically
survival of the fittest. Originally due to John Holland, the
three major processes of the genetic algorithm are crossover,
mutation, and selection.
Under the assumption of m = 1, one can model the control variable as a log-sigmoid function of the state variables:
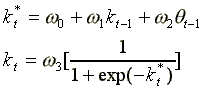 (7)
(7)
The logsigmoid function is widely used in neural network approximation
methods. As Sargent (1993) has pointed out, this function is
more accurate and parsimonious than polynomial methods. In
neural network estimation, the coefficient set [w] is obtained
through the backpropagation method. A random set of coefficients
is used to initialize the "learning", and the coefficient
vector is gradually adjusted through gradient search methods.
Marcet's PE method operates in a similar manner on the Euler
equation.
The genetic algorithm approach is different. It generates randomly not just one, but a large set of coefficient sets [w] , known as "bit strings", determined by a predetermined population size. From this population, randomly selected pairs are selected with replace, equal to one-half the population size. These randomly selected pairs are then recombined in a crossover mechanism. A random integer is selected for each crossover, and the bits from the two chosen sets of coefficients are then swapped with a probability Pc. Each pair, in this method, generates two children. A "tournament" then takes place, among the two parents and two children. The two best survive. The process is repeated until the population of seclected pairs is exhausted. What survives is a new generation, equal to the size of the previous generation. Some are "parents" from the previous generation, others are new children.
After the crossover process is complete, mutation is applied to the strings of "survivors" representing the new generation. The mutation operator is a stochastic bitwise complementation applied with a small uniform probability Pm.
The process is then repeated, applying a "roulette wheel" for selection to the next generation.
The very best coefficient set, after a given number of generations, is then chosen as the coefficient set for optimizing the model. Alternatively, the process can stop, after the fitness criterion applied to the best coefficient set or "bit string" , converges or fails to change by a given amount.
While it is clear from the process that only above average coefficient strings will survive successive populations, one can insure that the very best will survive for several generations by applying elitism. A given bit or coefficient string w(I*,k) from generation I*, ranking first in this generation, may not be chosen for crossover to generation I*+1. Under elitism, if the fitness criterion applied to all the members of generation I*+1 does not dominate w(I*,k), then w(I*,k) will be allowed to survive to generation I*+1.
As Hassoun (1995) points out, of the three genetic operators, the crossover is the most crucial for obtaining global results. It is responsible for mixing the partial information contained in the strings of the population.
The mutation operator, by contrast, diversifies the search and introduces new strings into the population, in order to fully explore the search space. However, the mutation operator cuts with a two-edge sword. Applying mutation too frequently will result in destroying highly fit strings in the population, and thus may slow down or impede convergence to a solution. Back has conjectured that the optimal mutation probability should be (1/n), where n is the number of coefficients or elements in a bit string or coefficient vector.
In our analysis, we set the permutation parameter at this number, .25. The crossover probability is set at .9, the population of "bitstrings" in each generation is set at 30, and to minimize on computing time, the maximum number of generations for finding the "fittest" bitstring is 10.
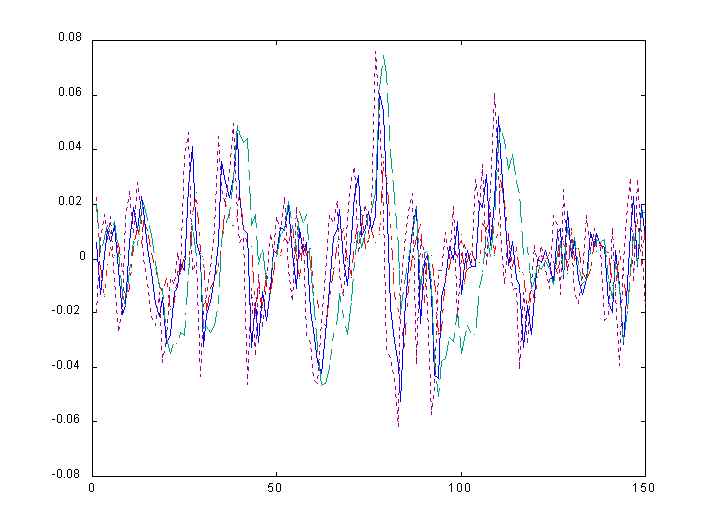
This paper examines the outcomes of the different methods, for given parameter values of the stochastic model:
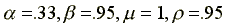
and with varying values of s (.01, .02, and .03) and t (.5,
1, 1.5). The results appear in the following section.
We first discuss the simulation results for the case of t=1,
when we can compare the exact solution path for consumption with
the paths given by the approximation methods. Then we compare
the paths for the cases of t=.5 and t=1.5. In all cases,
the solutions are filtered by the Hodrick-Prescott filter.
A. Analytical and Approximate Solutions
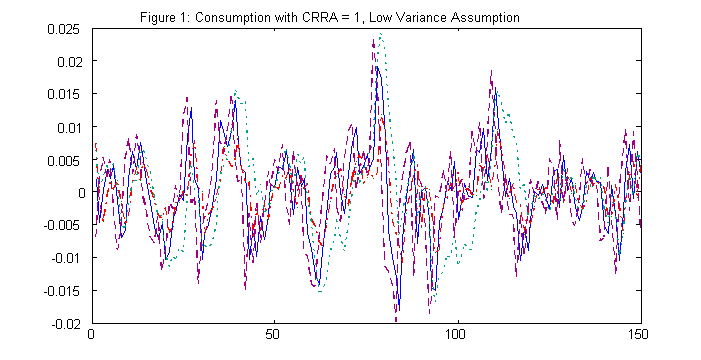
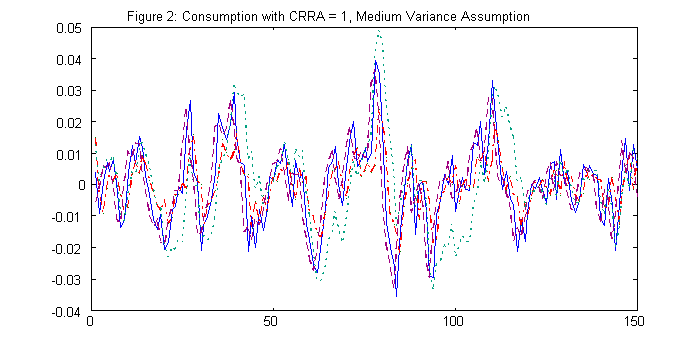
Figures 1, 2, and 3 give the paths of the exact (analytic),
the LQ, and log LQ, the PE, and the GA methods for the corresponding
cases of s = .01, .02, and .03 for consumption, for t=1. The
solid curve is for the exact solution, the broken curve is for
the PE path, the dotted curve is for the GA solution path, while
the mixed dotted and dashed curves are for the LQ solutions.
We present the summary statistics for these paths in Table I.
.
| Table I: Summary Statistics of the Exact, LQ, Log-LQ,PE and GA Solutions | |||||||||||||||||
| Sample Means | Sample Std. Deviations | Coefficient of Variation | |||||||||||||||
| Variance of Disturbance Term | Variance of Disturbance Term | Variance of Disturbance Term | |||||||||||||||
| Low Medium | High | Low Medium | High | Low Medium | High | ||||||||||||
| Exact | 0.0245 0.0246 0.0242 | 0.0065 0.0132 0.0201 | 2.6596 5.3822 8.2972 | ||||||||||||||
| LQ | 0.0210 0.0209 0.0211 | 0.0040 0.0080 0.0121 | 1.8916 3.8215 5.7256 | ||||||||||||||
| Log-LQ | 0.0632 0.0632 0.0630 | 0.0039 0.0079 0.0119 | 0.6241 1.2517 1.8883 | ||||||||||||||
| PE | 0.1569 0.1615 0.1606 | 0.0075 0.0151 0.0229 | 0.4752 0.9339 1.4266 | ||||||||||||||
| GA | 0.0240 0.0245 0.0246 | 0.0075 0.0125 0.0236 | 3.1047 5.1024 9.6126 | ||||||||||||||
| Correlation with Exact Solution | Distance Measure from Exact Solution | ||||||||||||||||
| Variance of Disturbance Term | Variance of Disturbance Term | ||||||||||||||||
| Low | Medium | High | Low-E04 | Med-E03 | High-E03 | ||||||||||||
| LQ | 0.6668 | 0.6669 | 0.6668 | 0.2362 | 0.097 | 0.2244 | |||||||||||
| Log-LQ | 0.6667 | 0.6666 | 0.6663 | 0.2364 | 0.0972 | 0.2252 | |||||||||||
| PE | 0.6298 | 0.6298 | 0.6276 | 0.3662 | 0.1504 | 0.3484 | |||||||||||
| GA | 0.4598 | 0.7888 | 0.4581 | 0.5315 | 0.0698 | 0.4974 | |||||||||||
The summary statistics show that the GA does better the other
methods, by the distance criteria, for the medium variance assumption,
with s=.02. For the other variance assumption, the PE method
beats the GA, but does not dominate the LQ. Since the GA was
implemented to minimize computational time, with only 10 generations,
further improvement may be possible.
Figures 4 and 5 present the paths of consumption for t = .5
and t= 1.5, for the three variance assumptions. The solid line
is for the LQ and log-LQ solutions, the broken line for the GA
solution, and the mixed dashed and dotted line for the GA solutions.
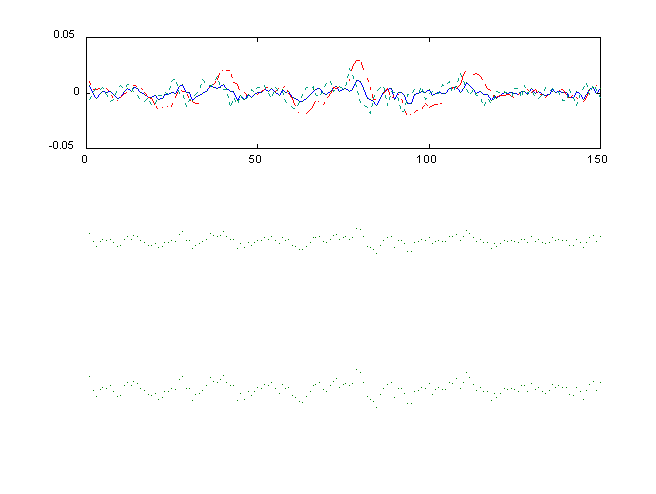
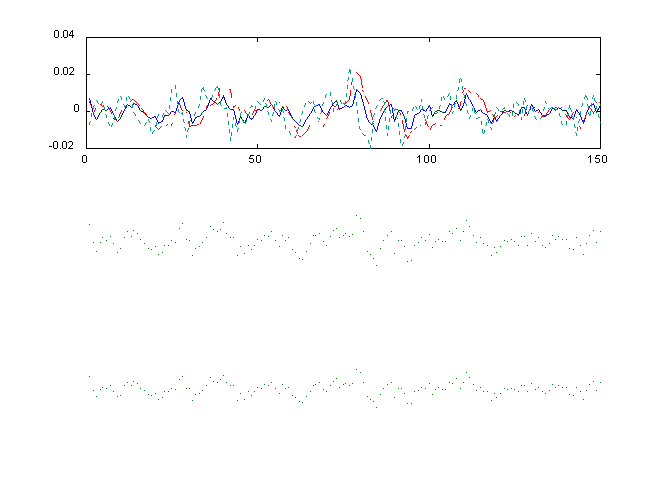
One notices that the higher t produces a somewhat flatter business
or consumption cycle, for both the PE and GA approximations.
Table II presents the summary statistics for these paths.
| Table II: Summary Statistics for the Approximations for CRRA = .5 and 1.5 | |||||||||||
| CRRA = .5 | |||||||||||
| Sample Means | Sample Std. Deviations | ||||||||||
| Variance of Disturbance Term | Variance of Disturbance Term | ||||||||||
| Low | Medium | High | Low | Medium | High | ||||||
| LQ | 0.0210 0.0209 0.0211 | 0.0040 0.0080 0.0121 | |||||||||
| Log-LQ | 0.0632 0.0632 0.0630 | 0.0039 0.0079 0.0119 | |||||||||
| PE | 0.1570 0.1606 0.1626 | 0.0098 0.0199 0.0303 | |||||||||
| GA | 0.0245 0.0243 0.0242 | 0.0071 0.0133 0.0223 | |||||||||
| CRRA =1.5 | |||||||||||
| Sample Means | Sample Std. Deviations | ||||||||||
| Variance of Disturbance Term | Variance of Disturbance Term | ||||||||||
| Low | Medium | High | Low | Medium | High | ||||||
| LQ | 0.0210 0.0209 0.0211 | 0.0040 0.0080 0.0121 | |||||||||
| Log-LQ | 0.0632 0.0632 0.0630 | 0.0039 0.0079 0.0119 | |||||||||
| PE | 0.1556 0.1603 0.1576 | 0.0064 0.0125 0.0191 | |||||||||
| GA | 0.0244 0.0244 0.0247 | 0.0075 0.0137 0.0214 | |||||||||
The results of Table II show that the GA gives estimates slightly
different than the PE method. For t = 1, the LQ method appears
to be an adequate approximation. However, for higher degrees
of relative risk aversion, both the LQ and log-LQ do not reflect
much effect on the standard deviation of consumption. Both the
PE and GE pick up these effects. However, the GA, as pointed
out above, predicts a much lower mean for the consumption path.
For this reason, our analysis suggests that the GA should at
least compliment the more common PE method for approximating business
cycle models with relatively high degrees of risk aversion.
Business cycle research with nonlinear stochastic dynamic models is an enterprise which is becoming more and more computationally intensive. We have tried to show how GA methods, which avoid the trap of local optima and take seriously inequality and other constraints, are ideally suited for solving these models as we learn in the profession how to incorporate risk and consequently higher degrees of nonlinearity.
Doubtless, too, the GA itself will adapt and evolve, perhaps
"mate" with PE methods, and help us to learn how to
solve these models more accurately than current methods.
Back, T. (1993), "Optimal Mutation Rates in Genetic Search",
in S. Forrest, ed., Proceedings of the Fifth International
Conference on Genetic Algorithms. San Mateo, Calif: Morgan-Kaufman,
2-8.
Bishop, Christopher M. (1995), Neural Networks for Pattern
Recognition. New York: Oxford University Press.
Cooley, T.F. and G.D.Hansen (1989), "The Inflation Tax in
a Real Business Cycle Model", American Economic Review 79,
733-748.
Den Haan, W.J. and A. Marcet (1994), "Accuracy in Simulations",
Review of Economic Studies 61, 3-17.
Goldberg, D. E. (1989), Genetic Algorithms in Search, Optimization
and Machine Learning. Reading, Mass: Addison-Wesley Publishing
Co.
Hassoun, Mohamad H. (1995), Fundamentals of Artificial Neural
Networks. Cambridge, Mass.: MIT Press.
Holland, J. (1975), Adaptation in Natural and Artificial Systems.
Ann Arbor: University of Michigan Press.
Marcet, A. (1993), "Simulation Analysis of Dynamic Stochastic
Models: Applications to Theory and Estimation", Working
Paper, Universitat Pompeu Fabra.
Sargent, Thomas J. (1993), Bounded Rationality in Macroeconomics.
New York: Oxford University Press.
Tauchen, G. and R.M. Hussey (1991), "Quadrature-Based Methods
for Obtaining Approximate Solutions to Non-linear Asset-Pricing
Models", Econometrica 59, 371-396.
Taylor, J.B. and H. Ulig (1990), "Solving Nonlinear Stochastic
Growth Models: A Comparison of Alternative Solution Methods",
Journal of Business and Economic Statistics 8, 1-17.
Uhlig, Harald (1997), "A Toolkit for Analyzing Nonlinear
Dynamic Stochastic Models Easily". Working Paper, CentER,
University of Tilburg.