ABSTRACT
Spatial Effects upon Employment Outcomes:
The Case of New Jersey Teenagers
Theories about the importance of space in urban labor markets have emphasized the role of employment access, on the one hand, and neighborhood composition, on the other hand, in affecting employment outcomes. This paper presents an empirical analysis which considers both of these factors, together with individual human capital characteristics and household attributes in affecting youth employment.
The analysis is based upon an unusually rich sample of micro data on youth in four New Jersey metropolitan areas. The empirical analysis is based on a sample of some 28,000 at home youth, matched to detailed census tract demographic information and specially constructed measures of employment access.
The research includes a comparison of the importance of neighborhood and access in affecting youth employment when individual and household attributes are also measured. The results demonstrate the overall importance of these spatial factors (particularly neighborhood composition) in affecting youth employment in urban areas.
I. Introduction
Two related bodies of research link the intra metropolitan distribution of households to labor market outcomes. These distinct perspectives extend the standard human capital model of labor markets to consider the effect of space on labor market operations, each presuming a somewhat different mechanism of causation. Research addressing the well-known "spatial mismatch hypothesis" focuses on the impact of job decentralization on the employment prospects of minority households who, through constraints on housing choices, are left behind. In this work, space affects the level and distribution of minority employment through proximity to jobs. As jobs increasingly decentralize and minorities remain concentrated in central cities, minority access to jobs declines, lowering their employment rates and earnings. While the evidence on the importance of the mismatch in jobs is not definitive, it continues to be a focus of scientific and policy interest (See Kain, 1992, and Holzer, 1991, for recent reviews).
A distinct hypothesis, associated with William Julius Wilson's (1987) work on the so-called "urban underclass," suggests that the social isolation resulting from the concentration of minorities has a negative effect on individuals more generally, and on their labor market performance specifically. While the empirical evidence on this mechanism is quite ambiguous (see Jencks and Mayers, 1990, for a review and Manski, 1993, for a critique), several recent empirical studies support some version of this hypothesis. Using different data but similar approaches, Brooks-Gunn et al (1993), Clark (1992), and Crane (1991) each found evidence of effects of neighborhood composition on youth high school dropout rates. More directly related to labor market concerns, Case and Katz (1991) analyzed data on poor neighborhoods within Boston, concluding that neighborhood peers substantially influence a variety of youth behaviors, including propensity to work. There are several mechanisms through which a neighborhood might affect labor markets (for example, the absence of positive role models, the lack of informal job contacts, the presence of disruptive influences). These differ from the presumed mechanism underlying the spatial mismatch hypothesis. According to this latter research, it is the internal composition of a neighborhood which matters, rather than the relationship of that neighborhood to external employment opportunities.
A unifying theme in all this research is that urban labor market outcomes are influenced by more than the individual characteristics recognized in the standard human capital model. Even beyond characteristics of the local labor market, this work suggests that information about the local residential environment may improve our models of urban labor market outcomes.
This paper provides tests of the relative importance of spatial factors. We develop and apply a standardized approach to measuring job access, one that can be duplicated for a large number of metropolitan areas. Using a unique data set created and analyzed within the Bureau of the Census, we estimate a series of employment probability models based on a standard human capital model. We then expand this model to include information on proximity to jobs and various neighborhood characteristics. This permits us to examine the importance of these spatial attributes, frequently omitted from other models. It also permits us to examine the relative importance of these spatial variables.
Throughout our analysis, we find strong evidence of the importance of spatial factors in determining youth employment outcomes. As for which factors matter most, our results suggest that they differ both by the outcome examined and the city.
II. Methodology
a. Data
Through arrangements with the U.S. Census, we have created a data set containing all records of non Hispanic white (white), non Hispanic black (black) and Hispanic youth (aged 16 to 19) residing with at least one parent, and located in one of the 73 largest metropolitan areas. In this paper, we report on an analysis of the urban labor markets in the state of New Jersey. We have all records, rather than just the 1/10 or 1/100 publicly available samples. Thus, even by limiting the analysis to one state, the sample contains more than 28,000 youth who reside in one of New Jersey’s four largest metropolitan areas (Newark, Bergan-Passaic, Middlesex, and Monmouth). The most important aspect of the data set is that each record in our 1990 extract is coded by census tract. We have matched this data set with aggregate census tract characteristics, such as the percent of the census tract which is poor, female headed, employed, black, etc. This generates a large sample of observations on youth and their labor market outcomes matched to a body of distinctly rich neighborhood context.
The second portion of the data is compiled from the transportation subsample of the 1990 Census, available at the tract level through the Census Transportation Planning Package (CTPP) for large MSAs. The CTPP provides direct information about commuting patterns and proximity to jobs at the census tract level. The raw data provided by the CTPP, matrices of zone-to-zone commuting patterns and peak commute times, are sufficient to create a variety of well-defined tract level measures of employment access. The derivation of these measures is discussed in Appendix B. These job proximity measures are linked to the individual record through tract identifiers, providing us with both neighborhood and job access information for all youth in the sample. As described in Appendix B, we have created several measures of employment access for each census tract in the four metropolitan areas. It is worth noting that these access measures are based on travel time, so they incorporate information on both spatial distance and transportation ease.
b. Statistical Model
The first step of the analysis is based on a logit model relating youth employment probabilities to individual and family characteristics:
(1) log [pi/(1-pi)] = a Xi ,
where Xi is a vector of those individual and family characteristics found by previous research to be relevant for youth employment outcomes. We then contrast results from this model with an expanded statistical model, which includes both job proximity and neighborhood characteristics:
(2) log [pi/(1-pi)] = a Xi + b Ai + g Ni ,
where Ai is a measure of employment access, and Ni is a vector of neighborhood (census tract) characteristics found to be important through previous empirical work. (For examples of similar work which has incorporated either job proximity or neighborhood characteristics in this fashion -- but not both -- see Ihlanfeldt and Sjoquist , 1990, Case and Katz ,1991, and Duncan, 1994.)
III. Results
We estimate equations (1) and (2) for the Newark MSA, examining probabilities of both employment and "idleness" (i.e., not-in-school-and-not-employed). First we analyze all youth, then white, black, and Hispanic youth separately. We then present the results of these models for all four metropolitan areas, investigating consistency in the effects of neighborhood and accessibility upon labor market outcomes.
a. Newark
Table 1A presents estimates of the youth employment model, equation (1), for all Newark youth, and for white, black, and Hispanic youth separately. Most results confirm previous findings. Females and older youth are more likely to be working. School enrollment decreases the likelihood of working, as does the birth of a child for teen-aged girls. Youth in female-headed households are somewhat less likely to be working, while those in a family with at least one parent working are also more likely to be working. Differences in the intercepts by race reveal lower employment probabilities for minority youths, particularly for black youth.
There is some variation in results across demographic groups. Racial groups differ somewhat in the specific measure of education which is most important in affecting employment outcomes. While the coefficient of the head of the household's education is always negative, it is not significant for blacks. The effect of household income (excluding the youth’s earnings) on employment follows a similar pattern. Increased family resources reduces youth employment.
Measuring the effect of family socioeconomic characteristics is complicated by the relationship between youth work and school decisions. While there is clearly some interdependence in these outcomes, we have simplified our estimation by treating school status as an exogeneous control. In terms of family socioeconomic status, higher status decreases the likelihood of in-school youth working, while increasing the likelihood for out-of-school youth.
To eliminate this problem we have also estimated this model using "idleness" (not-working-and-not-in-school) as the dependent variable. Table 1B reports the results of identical models (except the school-status variable is omitted). We expect that all variables indicating higher family socioeconomic status will decrease youth idleness. This expectation is borne out. The two sets of results are quite comparable. We include both outcome measures in our analysis, as spatial factors are likely to affect school and work decisions differently.
In the next step of the analysis, the logit model is expanded to include neighborhood information. We examine two categories: employment access and measures of "social access." Employment access is measured by an index of employment "potential" derived from the assumption that worktrip destinations are generated by a Poisson process. A lack of social access is indicated by various measures of neighborhood composition.
Preliminary analysis with a larger set of neighborhood variables established that one measure of racial composition (percent white) and four measures of tract poverty or employment levels (percent poor, on public assistance, unemployed and adults working) are consistently important in affecting outcomes. Table 2 presents the correlation coefficients of the relevant variables for Newark. Neighborhood demographic measures are highly correlated in Newark; with only one exception the correlation coefficients among these measures exceed 0.76. The job access measure is only weakly correlated with the demographic characteristics of neighborhoods.
The appropriate functional form for these variables is not known a priori. Indeed, it is possible that neighborhood effects matter after some threshold, affecting the logit of employment in a non-linear fashion. We estimated a series of models to test for non-linearities, and while there is some evidence that the relationship may be complicated, no non-linear representation seemed superior to simple continuous measures of neighborhood attributes. We report results using continuous measures.
We estimated a variety of models of youth employment probabilities with these neighborhood variables. The results for the individual and family level variables were essentially unchanged -- with the exception that family background variables generally decrease slightly in magnitude and statistical significance. This suggests that, while neighborhood characteristics may spuriously capture omitted family influences (Corcoran et al, 1992), the reverse is also the case. Empirical work which does not include information about neighborhoods likely overstates the (direct) influence of family characteristics on employment outcomes.
Results for the neighborhood variables are presented in Tables 3A and 3B. Panel A presents results for all youth, and Panels B through D present results separately for white, black, and Hispanic youth. In Model I of each panel and table, employment access is the sole neighborhood variable included. In the case of youth employment, improved job access has a significant and positive effect for all youth, and for black youth. For youth idleness, job access is highly significant for all youth and for black youth.
The independent effect of access does not persist when other neighborhood characteristics are added, singularly (Models II - VI) and in pairs (Models VII - X). In almost every case, the measure of access to jobs is insignificant when measures of neighborhood racial composition or neighborhood poverty/employment are included. In the sample of all Newark youth, each neighborhood variable, when entered individually, is significant and is of the expected sign. This is also true for the separate samples of white and black youth.
The high correlation among many of the neighborhood variables means that the relative importance of neighborhood measures cannot be determined with precision. While employment access is not particularly highly correlated with the other tract variables, the correlations among the other variables are quite high. The effect of this is illustrated in the results of models VII - X, for white youth employment (Table 3A, Panel B). Each neighborhood composition measure is significant when included separately. However, when pairs of variables are included, generally neither neighborhood variable is significant. Note, however, according to a standard likelihood ratio test, the set of measures is significantly different from zero. In the aggregate for youth employment and for black youth separately (both employment and idleness), it does appear that neighborhood poverty/employment characteristics have a stronger effect than does the racial composition of the neighborhood. However, idleness of Hispanic youth appears more strongly influenced by neighborhood racial composition.
Some caution is in order in evaluating these results. Several recent papers have highlighted the difficulty of controlling adequately for family characteristics and choice when identifying neighborhood and other potential influences on social outcomes (Corcoran et al, 1992, Evans et al, 1992, and Plotnick and Hoffman, 1995). Other work has emphasized the circumstances in which the logic of the identification of peer influences is problematic (Manski, 1993, 1995). The potential endogeneity of neighborhoods is also a source of concern in this empirical work. There are several ways in which endogeneity may be manifest. Our empirical analysis is more successful in dealing with some sources of this simultaneity than others.
The most obvious source of statistical problems in the interpretation of findings about youth employment is the omission of individual or family characteristics. In particular, family variables have been shown to be very important determinants of youth outcomes (Corcoran et al, 1992), yet are frequently omitted from empirical work. Since family characteristics are likely to be correlated with neighborhood characteristics, it is possible that measures of neighborhood characteristics are merely proxies for family effects. By using only at-home youth, we have access to the range of census information on the youth's family. These attributes really "matter" in the empirical results.
A second source of concern is the youth's choice of neighborhood. Here again, by limiting attention to at-home youth, we can presume that this choice is made by the parent(s), using the standard transportation-housing cost calculus. Household choice is exogeneous to the transport demands of youth. Of course, to the extent that household choices about residential location are influenced by the impact of neighborhood characteristics on youth employment, a focus on at-home youth will not eliminate this source of simultaneity.
A third source of concern is the definition and computation of the accessibility measure itself. We should emphasize that this measure is not computed from the observed commuting patterns of teenagers. Nor is it computed with reference to the location of jobs which might be "suitable" for teenagers (Ihlanfeldt and Sjoquist, 1989). It is merely the "standard" accessibility measure calculated from observations on the worktrip patterns of all workers -- adults and teenagers of all races -- within the urban area.
This attention to specification does not, of course, eliminate all sources of simultaneity. To the extent that there are omitted family or individual characteristics which are more strongly correlated with neighborhood variables than with other included controls, the results may be spurious. It is also possible that the residence choices of others in a neighborhood are influenced by youth employment outcomes, affecting the characteristics of the neighborhood indirectly. In Appendix C, we present direct tests for the existence of this indirect relationship for Newark youth. We find little evidence of such a spurious relationship.
The high correlation among the various neighborhood characteristics raises a second issue in interpreting these results. Given the high correlation among neighborhood characteristics, it is difficult to separate the effects of various dimensions of related neighborhood characteristics with any precision. For models in which we include one neighborhood characteristic, this measure acts as a proxy for a collection of characteristics, and the results should be interpreted in that light.
B. New Jersey Cities
In this section, we expand the sample to include all four metropolitan areas in New Jersey. We estimate similar statistical models, but with larger samples and somewhat lower levels of intercorrelation of neighborhood demographic measures. Table 4 presents a subset of the results for all metropolitan New Jersey youth, which convey the main findings. Panel A includes results for the estimation of employment probabilities, Panel B summarizes results for the estimation of idleness probabilities.
Model I reports estimates of youth employment probabilities as a function of neighborhood access measures, individual, and household characteristics. The cardinal values of the access measure are hardly comparable across MSAs (see Appendix B and Table 5), so we permit the coefficient on access to vary by MSA. Employment access has a highly significantly positive effect on youth employment in each of the four MSAs.
The other five models include access, but introduce other neighborhood characteristics. Models II-IV include the percent white, the percent on public assistance, and the percent of adults not-at-work, respectively, in the census tract of residence. Each of these neighborhood composition variables is significant and is of the expected sign. Including these characteristics has little impact on the access coefficients. In Models V and VI, which include the access measures, percent white, and one of the two poverty/employment measures, the results are comparable. Both neighborhood composition variables are significant, and the access measure is important in each of the four cities.
In Panel B, the results for predicting teenage idleness differ slightly. The access measure is significant in the simplest model (Model I), but in more complex specifications, access appears to be less important. Individually, and in pairs, other neighborhood measures have important effects upon the probability of idleness of urban youth.
It is certainly possible that the effect of neighborhood composition differs across metropolitan areas. We have investigated models of this general specification (see Appendix Table 1). On purely statistical grounds, the complete disaggregation of neighborhood measures across MSAs does improve the employment probability model, but does not improve the idleness results. The magnitudes, however, are essentially the same.
IV. Implications
The statistical results for this sample of New Jersey youth suggest that neighborhood composition and employment access affect labor market outcomes, although the quantitative estimates differ by area and by outcome. The character of urban neighborhoods and the effect of neighborhood composition on outcomes varies across metropolitan areas. This accounts for some of the observed differences in youth employment outcomes. Moreover, within metropolitan areas, there are large differences in average characteristics of neighborhoods in which youth of different race and ethnicities reside. For example, in Newark, 81.5 percent of white youth live in census tracts in which 90 percent or more of the population is white. In contrast, slightly less than 20 percent of Hispanic youth, and only 4 percent of black youth live in such tracts. Table 5 summarizes the average characteristics of neighborhoods in which youth of different races reside. These differences may lead to large differences in employment outcomes for youth.
Table 6 indicates the importance of these differences in employment access and neighborhood demographics in affecting employment outcomes by race and ethnicity. The first column in the table presents the employment probability estimated for the "average" youth in each of these four metropolitan areas. The second column presents the employment probability of the same "average" youth living in the neighborhood in which the average white youth resides, in each metropolitan area. The third and fourth columns present the employment probabilities estimated for the same youth living in the neighborhood inhabited by the average white, black, and Hispanic youth, respectively. Panel B presents the same simulation using idleness instead of employment. Many of these differences are quite large.
In Bergan-Passaic, residence in the neighborhood in which the average white youth lives (compared to that in which the average black lives) increases youth employment rates by 2.3 percentage points, from 39.9 to 42.2 percent. A similar comparison of employment rates for those living in the average white and average Hispanic neighborhood leads to a smaller difference. In Middlesex the differences are approximately of the same magnitude (a 2.8 percentage point increase for white-black comparisons, and a 3.9 percentage point increase for the white-Hispanic comparison). In Monmouth, located on the New Jersey shore, differences in average neighborhood characteristics have much smaller effects on youth employment rates, while in Newark, the effect is strikingly large. In Newark, predicted employment rates for the average white neighborhood are almost 33 percent higher than for the average black neighborhood.
Results for youth idleness are comparable. In general, the largest disparities are between probabilities for the average white and the average black neighborhoods. Across these MSAs, the effect varies, and is greatest for the largest and most urban metropolitan area in our sample, Newark.
V. Conclusion
This paper analyzes employment and "idleness" outcomes for a large sample of urban youth. The analysis is based upon observations on at-home youth and their families, the employment access of the neighborhood in which they reside, and the socio-economic character of those neighborhoods.
The analysis documents the importance of human capital and family attributes in conditioning the labor market outcomes for youth living at home. In addition to individual-level determinants, we find evidence of substantial spatial linkages to employment outcomes. While not consistently significant across metropolitan areas, measures of access to jobs are important in affecting employment in some areas, especially for minority youth. Access appears to play essentially no role in determining youth idleness, an outcome dominated by youth school-enrollment status. Furthermore, whether as measures of social access, role models, or peer influence, neighborhood composition matters consistently. Measures of the presence of employed, and non poor individuals (presumably those with knowledge of and contact with jobs) affect youth employment. Even with large samples of data, we are less successful in distinguishing among these distinct, but closely related, potential causes.
Simulations using these results demonstrate quite clearly that the constellation of factors which distinguish "good" from "bad" neighborhoods affect teenage employment in profound ways.
Appendix B: The Computation of Spatial Access
In the text, we employ a measure of the accessibility of each census tract to employment locations. This measure is derived from the "potential access" measures widely used by transport planners (see Isard [1960] for an early review or Smith [1984] for a more recent treatment). These measures are derived from observations on the work trip patterns of commuters and the transport linkages in an urban area.
The accessibility measures are based upon the data available through the Census Transportation Planning Package (CTPP) for large metropolitan areas. The CTPP data are obtained from the Transportation Supplement of the 1990 Census. Each metropolitan area is divided into Traffic Analysis Zones (TAZ’s). Zone-to-zone peak commute flows (Tij) as well as peak travel times (dij) are reported. From the elements of the matrix, the number of workers resident in each TAZ (Ri) can be estimated (![]() ). Similarly, the number of individuals working in each zone (Wj) can be estimated (
). Similarly, the number of individuals working in each zone (Wj) can be estimated (![]() ).
).
The most widely used empirical model of the accessibility of particular residential locations is based upon the gravity concept:
(B1) ![]() ,
,
where Greek letters denote parameters. Isard (1960) provides a number of physical and social scientific justifications for the formulation. Flows between i and j are positively related to the "masses" of residences and workplaces and inversely related to the "distance" (travel time) between i and j.
Estimates of the parameters yield a measure of the accessibility of each residence zone to the workplaces which are distributed throughout the region (Isard, 1960, p. 510), i.e.,
(B2) ![]() ,
,
where ![]() is computed from the parameters estimated by statistical means.
is computed from the parameters estimated by statistical means.
More sophisticated measures of access recognize that the transport flows to each destination are count variables. The Poisson distribution is often a reasonable description for counts of events which occur randomly.
Assuming the count follows a Poisson distribution, the probability of obtaining a commuting flow Tij is
(B3) ![]() !
!
where l ij is the Poisson parameter. Assuming further that
(B4) ![]() ,
,
yields an estimable form of the count model (since E(Tij) = l ij). See Smith (1987) for a discussion. Estimates of the parameters similarly yield a measure of the accessibility of each residence zone to workplaces in the region
(B5) ![]() .
.
A more general model of the flow count between i and j relaxes the Poisson assumption that the mean and variance are identical. For example, following Greenwood and Yule, Hausman, Hall, and Griliches (1984, p. 922) assume that the parameter l ij follows a gamma distribution G(w ij) with parameters w ij. They show that, under these circumstances, the probability distribution of the count is negative binomial with parameters w ij and h ,
(B6) 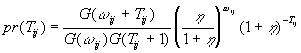
Again, assuming that
(B7) ![]()
yields an estimable form of the count model and the resulting accessibility index for each residence zone.
The count models are clearly nested. If h is infinitely large, then equations (B6) and (B7) specialize to (B3) and (B4). If h is finite, then the mean and the variance of the count variables are not identical (as assumed by the Poisson representation).
The accessibility measure derived from the gravity model, equations (B1) and (B2), may be interpreted as a simple linear approximation to either of these theoretical count models. (Smith [1987] provides a thorough discussion of the link between gravity and Poisson models.)
Table B1 presents parameter estimates of the three models for four metropolitan areas in New Jersey. The models are estimated using the CTPP data from the 1990 Census. For each of these metropolitan areas, the TAZ’s are coterminous with census tracts. The matrices of tract-to-tract commuting flows are sparse, with many zeros. For example, for the Newark metropolitan area there are 448 census tracts. Of the 200,704 possible commuting patterns (i.e., 448 times 448), 168,547 of them are zero. (In part, this reflects the fact that the underlying counts and transportation times are gathered from a sample of about fifteen percent of the population.) The estimates of the negative binomial and Poisson models are
obtained by maximum likelihood methods, adjusting the likelihood function for this truncation. In contrast, the gravity model is estimated in the most straightforward manner -- by applying ordinary least squares to equation (B1) in logarithmic form using the non zero observations.
As the table indicates, the hypothesis of Poisson flows is rejected in favor of the negative binomial. In each case, the estimate of h is rather precise, and it implies that the ratio of the variance to the mean ([1 + h ]/h ) is on the order of 2.5 or 3.
Table B2 presents the correlations among the census tract accessibility measures derived from the three models. Although the negative binomial model fits the data better than the Poisson model, the differences in the accessibility measures computed from them are very small. Similarly, the table shows that, for each of the four New Jersey metropolitan areas, the gravity model yields an almost identical measure of census tract access to employment.
Appendix C: Explicit Tests for Endogeneity
As noted in the text, a major concern in designing and interpreting the statistical models of labor market outcomes is the exogeneity of the neighborhood variables which have been measured. The statistical models have been designed to guard against the possibility that these geographical indicators are endogeneous to labor market choices. We address the simultaneity issue by considering the decisions of "at home" youth, whose residence choices have been made by parents, and by relying upon extensive measures of household demographics. Despite this, the possibility remains that some unobserved characteristics of households affect both neighborhood choices and youth employment choices.
This appendix provides further evidence on the exogeneity of neighborhood characteristics based upon the Hausman specification test.
In the text, four variables are used to measure aspects of urban neighborhoods: percent white (X1), percent receiving public assistance (X2), percent of adults not at work (X3), and the census tract access measure (X4). These variables are used in a variety of logit specifications. The most general of these are two logit models including three of the measures: (X1, X2, and X4) and (X1, X3, and X4).
We construct instruments for each of these four variables. We then include the instruments, together with the original variables in the logit model, and finally test the joint significance of the instruments. The hypothesis that the neighborhood variables are jointly exogeneous can be tested using standard likelihood ratios.
As instruments, we use census tract measures correlated with each of these four neighborhood indicators but not themselves determinants of employment choice. For percent white, we use as an instrument the tenure of the household and the percentage of housing of that tenure type in the tract. (There is abundant evidence that, for reasons of permanent income, racial discrimination, etc., minority households, ceteris paribus, differ systematically in tenure type from white households. But, practically no one would argue that homeownership causes higher levels of employment.)
For the percent receiving public assistance and the percent of adults not at work, we use a measure of the availability of appropriately sized units, conditioning on household size.
For the access measure, we employ the fraction of workers of common industry and occupation in the MSA residing in the tract. This is a measure of the heterogeneity of industry or occupation of any household member.
Table C1 reports the results of the Hausman specification test for Newark youth in differing age groups. The tests are constructed separately for in-school and out-of-school youth and for all youth.
As the table indicates, in no case can we reject the hypothesis of the exogeneity of the neighborhood influences at the 0.01 level. At the 0.05 level, we can reject the hypothesis of exogeneity for in-school youth of one of the models, but not the other.
As shown in the table, when the model includes a variable measuring the percent on public assistance, the c 2 is significant. However, when the model includes a variable measuring the percent of adults not at work -- perhaps a superior measure of the availability of informal information about employment opportunities -- each of the three measures of neighborhood effects upon teenage employment is shown to be exogeneous, according to conventional statistical criteria.
REFERENCES
Brooks-Gunn, Jeanne, George J. Duncan, Pamela K. Klebanov and Naomi Sealand, 1993, "Do Neighborhoods Influence Child and Adolescent Development?," American Journal of Sociology (2): 353-395.
Case, Anne and Lawrence Katz, 1991, "The Company You Keep: The Effects of Family and Neighborhood on Disadvantaged Youths," NBER Working Paper #3705.
Clark, Rebecca, 1992, "Neighborhood Effects on Dropping Out of School among Teenage Boys," The Urban Institute, Discussion paper series, PSC-DSC-UI-13.
Corcoran, Mary, Roger Gordon, Deborah Laren and Gary Solon, 1992, "The Association between Men's Economic Status and their Family and Community Origins," Journal of Human Resources 27(4): 575-601.
Crane, Jonathan, 1991, "The Epidemic Theory of Ghettos and Neighborhood Effects on Dropping Out and Teenage Childbearing," American Journal of Sociology.
Duncan, Greg J., 1994, "Families and Neighbors as Sources of Disadvantage in the Schooling Decisions of White and Black Adolescents," American Journal of Sociology 103: 20-53.
Ellwood, David, 1986, "The Spatial Mismatch Hypothesis: Are There Teenage Jobs Missing in the Ghetto?," in Richard B. Freeman and Harry J. Holzer, eds., The Black Youth Employment Crisis.
Evans, William, Wallace Oates and Robert Schwab, 1992, "Measuring Peer Group Effects: A study of Teenage Behavior," Journal of Political Economy 100(5): 966-991.
Freeman, Richard, 1982, "The Economic Determinants of Geographic and Individual Variation in the Labor Market Position of Young Persons," in Richard B. Freeman and David A. Wise (eds.), The Youth Labor Market Problem: Its Nature, Causes, and Consequences, Chicago: University of Chicago Press.
Hausman, Jerry, Bronwyn H. Hall, and Zvi Griliches, 1984, "Econometric Models for Count Data with an Application to the Patents - R&D Relationship," Econometrica 52(4): 909-938.
Holzer, Harry J., 1991, "The Spatial Mismatch Hypothesis: What Has the Evidence Shown?," Urban Studies 28(1): 105-122.
Ihlanfeldt, Keith R., and David L. Sjoquist, 1990, "Job Accessibility and Racial Differences in Youth Unemployment Rates," American Economic Review 80: 267-276.
Ihlanfeldt, Keith R., 1993, "Intra-Urban Job Accessibility and Hispanic Youth Unemployment Rates," Journal of Urban Economics, 33: 254-271.
Isard, Walter, 1960, Methods of Regional Analysis, Cambridge, MA: The MIT Press.
Jencks, Christopher and Susan Mayers, 1990, "The Social Consequences of Growing Up in a Poor Neighborhood," in Laurence E. Lynn, Jr. and Michael McGeary, eds., Inner City Poverty in the United States, Washington, DC: National Academy Press.
Kain, John F., 1992, "The Spatial Mismatch Hypothesis: Three Decades Later," Housing Policy Debate 3(2): 371-462.
Leonard, Jonathan S., 1987, "The Interaction of Residential Segregation and Employment Discrimination," Journal of Urban Economics 21: 323-346.
Manski, Charles F., 1993, "Identification of Endogeneous Social Effects: The Reflection Problem," Review of Economic Studies 60: 531-542.
O'Regan, Katherine M. and John M. Quigley, 1995, "Teenage Employment and the Spatial Isolation of Minority and Poverty Households," Paper presented at the Western Economic Association meetings, San Diego.
Plotnick, Robert and Saul Hoffman, 1995, "Fixed Effect Estimates of Neighborhood Effects," University of Washington.
Popkin, Susan J., James E. Rosenbaum, and Patricia M. Meaden, 1993, "Labor Market Experiences of Low-Income Black Women in Middle-Class Suburbs: Evidence from a Survey of Gautreaux Program Participants," Journal of Policy Analysis and Management 12(3): 556-573.
Raphael, Steven, 1995, "Intervening Opportunities, Competing Searches, and the Intra Metropolitan Flow of Male Youth Labor," unpublished paper, University of California, Berkeley.
Smith, Tony E., 1984, "Testable Characterizations of Gravity Models," Geographical Analysis 16: 74-94.
Smith, Tony E., 1987, "Poisson Gravity Models of Spatial Flows," Journal of Regional Science 27(3): 315-340.
Weber, James S. and Ashish K. Sen, 1985, "On the Sensitivity of Gravity Model Forecasts," Journal of Regional Science 25(3): 317-336.
Wilson, William J., 1987, The Truly Disadvantaged: The Inner City, The Underclass, and Public Policy, Chicago, Illinois: University of Chicago Press.
Appendix Table 1
Neighborhood Determinants of Employment Outcomes for New Jersey Youth *
(28191 Observations)
(t-ratios in parentheses)
I II III IV V VI
A. Employment --- --- --- --- --- ---
Chi-squared 3848 3904 3913 4002 3931 4021
-2logL 35233 35177 35168 35079 35150 35060
access:
Bergen-Passaic 0.066 0.068 0.069 0.070 0.069 0.071
(3.45) (3.49) (3.52) (3.63) (3.51) (3.65)
Middlesex 0.026 0.276 0.023 0.017 0.028 0.021
(2.17) (2.34) (1.99) (1.39) (2.38) (1.74)
Monmouth 0.006 0.007 0.006 0.007 0.008 0.008
(1.86) (2.25) (1.96) (2.07) (2.38) (2.35)
Newark 0.004 0.002 0.001 0.001 0.001 0.001
(3.37) (1.88) (0.45) (0.99) (0.51) (0.71)
percent white:
Bergen-Passaic 0.156 0.229 0.027
(1.17) (1.06) (0.19)
Middlesex 0.819 0.893 0.731
(3.86) (2.96) (3.38)
Monmouth -0.210 -0.691 -0.268
(0.94) (2.30) (1.19)
Newark 0.592 0.203 0.225
(6.43) (1.63) (2.26)
percent public assistance:
Bergen-Passaic -0.269 0.443
(0.42) (0.42)
Middlesex -2.798 0.521
(2.48) (0.32)
Monmouth -0.760 -2.785
(0.87) (2.38)
Newark -0.753 -2.248
(7.62) (4.58)
percent adults not at work:
Bergen-Passaic -2.049 -2.140
(3.58) (3.60)
Middlesex -1.536 -1.261
(3.25) (2.62)
Monmouth -1.059 -1.115
(2.99) (3.14)
Newark -3.579 -3.285
(11.03) (9.24)
*Note: Logit models include household level variables reported in Tables 1A and 1B.
Each model also includes separate intercepts for the different metropolitan areas.
Appendix Table 1 (continued)
Neighborhood Determinants of Employment Outcomes for New Jersey Youth *
(28191 Observations)
(t-ratios in parentheses)
I II III IV V VI
B. Idleness --- --- --- --- --- ---
Chi-squared 27913 27955 27960 27944 27970 27969
-2logL 11167 11126 11121 11137 11110 11111
access: -0.026 -0.011 -0.004 -0.026 -0.005 -0.010
Bergen-Passaic (3.58) (0.27) (0.10) (0.66) (0.11) (0.25)
-0.003 -0.001 0.003 0.010 0.004 0.011
Middlesex (0.11) (0.04) (0.12) (0.35) (0.16) (0.39)
0.001 0.002 0.002 0.000 0.001 0.001
Monmouth (0.14) (0.25) (0.26) (0.03) (0.21) (0.21)
-0.007 -0.003 0.000 -0.002 0.000 -0.001
Newark (3.16) (1.37) (0.13) (0.78) (0.08) (0.23)
percent white:
Bergen-Passaic -0.690 -0.543 -0.676
(3.25) (1.61) (2.98)
Middlesex -0.855 -0.255 -0.651
(2.42) (0.41) (1.77)
Monmouth -0.811 -0.198 -0.752
(2.31) (0.38) (2.14)
Newark -0.986 -0.614 -0.808
(6.23) (3.13) (4.71)
percent public assistance:
Bergen-Passaic 2.179 0.882
(2.34) (0.58)
Middlesex 4.114 4.033
(2.22) (1.24)
Monmouth 3.192 3.297
(2.37) (1.65)
Newark 3.077 2.007
(6.35) (3.28)
percent adults not at work:
Bergen-Passaic 0.955 0.329
(0.96) (0.30)
Middlesex 2.265 2.108
(2.25) (2.00)
Monmouth 0.909 0.908
(1.36) (1.33)
Newark 2.400 1.590
(4.88) (2.94)
*Note: Logit models include household level variables reported in Tables 1A and 1B.
Each model also includes separate intercepts for the different metropolitan areas.
Table C1
Tests of Exogeneity of Neighborhood Influences upon
Employment Outcomes for Newark Teenagers*
c 2 Statistics
|
Age Group |
In School Youth |
Out of School Youth |
All Youth |
A. Neighborhood Influences: Percent White, Access, Percent on Public Assistance
|
Ages 16 - 20 |
8.045 |
3.669 |
7.513 |
|
Ages 16 - 19 |
8.596 |
2.347 |
6.027 |
|
Ages 17 - 20 |
9.397 |
4.014 |
7.343 |
|
Ages 17 - 19 |
10.146 |
3.908 |
5.395 |
B. Neighborhood Influences: Percent White, Access, Percent Adults not at Work
|
Ages 16 - 20 |
4.536 |
3.895 |
5.114 |
|
Ages 16 - 19 |
4.303 |
2.364 |
3.294 |
|
Ages 17 - 20 |
5.846 |
4.529 |
5.169 |
|
Ages 17 - 19 |
5.616 |
4.439 |
2.772 |
*The critical values of c 2 with 3df are 7.810 and 11.300 respectively at the 0.05 and 0.01 levels of confidence.
Table B1
Parameter Estimates of Negative Binomial, Poisson, and Gravity
Models of Transport Access
(Asymptotic t ratios in parentheses)
|
A. Negative Binomial |
Newark |
Bergan Passaic |
Middlesex |
Monmouth |
|
a |
1.249
|
0.529
|
0.073 |
0.793
|
|
b |
0.342
|
0.474
|
0.545 |
0.421
|
|
g |
0.341
|
0.378
|
0.384 |
0.445
|
|
d |
0.705
|
0.842
|
0.856 |
0.872
|
|
h |
0.555
|
0.587
|
0.527 |
0.608
|
|
log likelihood |
-116818 |
-71835 |
-63415 |
-56296 |
|
B. Poisson |
||||
|
a |
-0.187
|
-1.557
|
-1.327 |
-0.991
|
|
b |
0.511
|
0.718
|
0.666 |
0.530
|
|
g |
0.424
|
0.474
|
0.465 |
0.598
|
|
d |
0.806
|
0.967
|
0.894 |
0.918
|
|
log likelihood |
-296466 |
-209995 |
-174066 |
-156235 |
|
C. Gravity Model |
||||
|
a |
0.601
|
-0.371
|
-0.337
|
-0.796
|
|
b |
0.307
|
0.427
|
0.473
|
0.486
|
|
g |
0.274
|
0.325
|
0.313
|
0.358
|
|
d |
0.485
|
0.569
|
0.622
|
0.593
|
|
R2 |
0.225 |
0.245 |
0.280 |
0.293 |
|
Number of observations |
32157 |
18419 |
16760 |
15009 |
Table B2
Simple Correlation Coefficients among Census Tract
Access-to-Employment Measures Derived from Negative
Binomial, Poisson, and Gravity Models
|
Gravity vs Poisson |
Gravity vs Binomial |
Binomial vs Poisson |
|
|
Newark
|
0.980 |
0.994 |
0.988 |
|
Bergan-Passaic
|
0.982 |
0.993 |
0.995 |
|
Middlesex
|
0.973 |
0.989 |
0.976 |
|
Monmouth
|
0.909 |
0.989 |
0.954 |