Key Words: Fisher Ideal Index, Historical
Price Indexes, Historical Quantity Indexes, Splicing
I'm afraid I may not really stick to the CPI. I would like to say something slightly different from what other people are going to be saying here.
Regarding the CPI and the Bureau of Labor Statistics, I guess I should mention that, in terms of my contact with the research that comes from the Bureau of Labor Statistics, going back to the 8 years that I was at the Federal Reserve Board in Washington, it's been my impression that for at least the past 20 years, up to and including the present time, the people who have the most expertise in index number theory in Washington, DC, are at the BLS. In addition, I've been one of the associate editors of the Journal of Business and Economic Statistics, an American Statistical Association journal, since it was founded, and I've handled many of the submissions that come from staff members at the BLS. Despite the fact that there are so many people who feel itís fashionable to pick on the BLS these days, my view is the exact opposite. They have a disproportionate amount of the expertise in Washington. They do now; they always have.
That was why we went to Jack Triplettís seminar. We came there from all over Washington, all of the agencies, to attend that seminar because that's where the expertise was. Jack was, of course, there.
In terms of the papers that were provided to these panelists, looking through them, I see the same thing--substantially higher expertise than I see from other agencies in Washington, as well as in the submissions I handle at the JBES, what I see in the Monthly Labor Review, etc. Regarding what the Commission is doing, similarly, I see very high expertise.
So my view is that relative to the objectives that people are focusing on these days, which I would view as directed towards a Congressional audience, the expertise is extremely high. I have tremendous confidence in these people, so I don't particularly wish to criticize them. I think they're the best.
Instead I would like to say something different. I would like to say that the CPI and other data that comes from the BLS and from other agencies in Washington go to many audiences, not only to Congress. One of the audiences is you people--the membership of the American Statistical Association, also the membership of the American Economic Association and the Econometric Society. We have a somewhat different reason for wanting this data--we use it in our research.
There isn't one CPI that's best for everybody. For example, the AARP is not terribly interested in the price of roller blades.
I want to talk about what researchers would like to see in their data. I would like to suggest that there is more that could be done in Washington in the interest of researchers, and I understand that we're perhaps not the most important of their customers. But we're among them.
First of all, in terms of the way that data are clustered into aggregates, in economic theory we know what the relevant clustering criterion is. It's called block-wise weak separability. I see very little about that in publications that come out of Washington in terms of tests for block-wise weak separability, or even evidence of recognition that that's the relevant admissibility condition for having the data be internally consistent with the models within which they are used. I'm not suggesting that the data should be reclustered, but I'd kind of like to see a bit more mention of this, perhaps, in publications and documents that come out of Washington.
What I primarily want to talk about is something else, and I realize that this is perhaps not high on the list of priorities of people in agencies in Washington, but to a statistician, sample size is very important. In addition, to economists, especially people working on endogenous growth, very long time series are important. Romer, for example, talks about dramatic decrease in volatility. This is mostly seen in very, very long time series of data.
The data in Washington are usually maintained going back to the date at which the data's maintenance was begun in Washington. But that's not where the data actually began--it began before that. A lot of historical data is over in the NBER. It comes from people like Kuznets, and others who have published books that go back to the 1860s.
This country, for research purposes, could easily have a database in excess of 100 years. Sweden does; it has for a long time. But we don't, because the Commerce Department, for example, begins its data in 1929. Now linking this to, say, Kuznets data that goes back to the 1860s is not so easy, because that data was not aggregated the same, splicing it is not so easy, etc.
But to indicate that this can be done, and that Washington could be providing this to us, I asked two of my students, Barry Jones and Travis Nesmith, who are interns at present at the St. Louis Federal Reserve, to make an attempt at it, and they did. I want to show you what happens, in the little time that I have, when one links Kuznetsís data to Commerce Department data, to see price and quantity data going back, way back, to the 1860s.
This is only an initial attempt at this, so I should mention that when we do a better job of this, perhaps we'll make it available, possibly through the St. Louis Federal Reserve Bank, which is funding some of this research of my students
But this is the way we've done it initially. We used Kuznetsís data, we linked it in 1929 to Commerce Department data. There's a handout I've provided to the panelists on the data sources and splicing details (available upon request).
The method of splicing is one that's become very popular by one of Erwin Diewert's publications. It is called the method of symmetric means, and we provided some references on this.
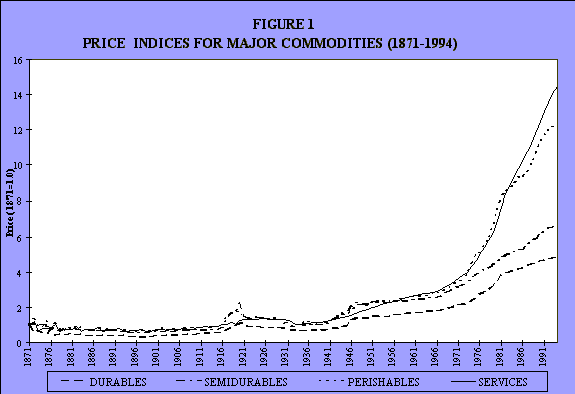
My two graduate students worked very hard on this and here it is, at least an initial attempt (see Figure 1). This can be improved upon, and we intend to do so. Going back, way back into the 1800s, it's possible to get prices for major commodities. We did this in four categories: durables, semidurables, perishables, and services.
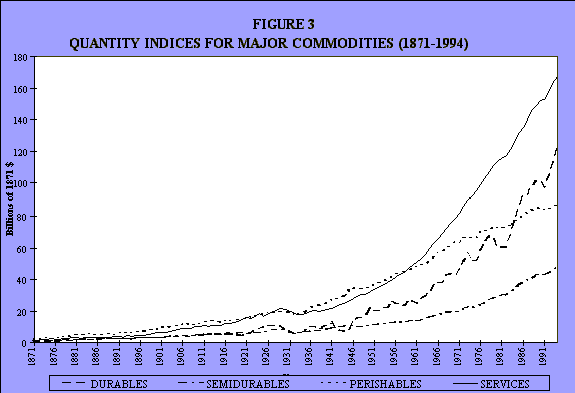
These are the corresponding quantities that are associated with those prices (see Figure 3).
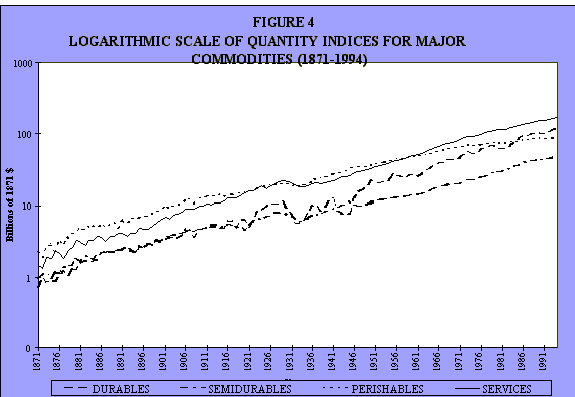
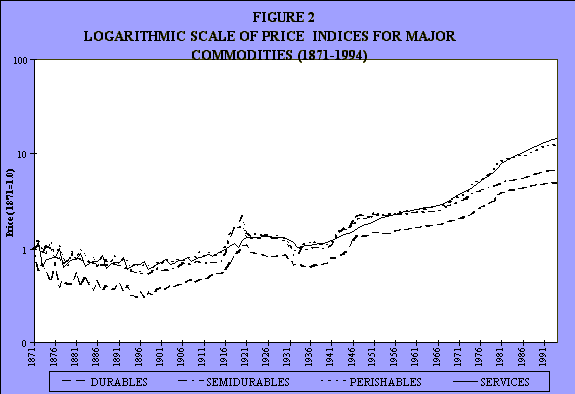
This is changing it to a semilogarithmic scale (see Figures 2 and 4). It's the same data. Because of the time constraint I just want to show you this very quickly, simply to indicate that it can be done. Not that I want to make any big deal out of this, but I want to indicate that this is at least possible. Here's an initial attempt at it. So there are the price and quantity components.
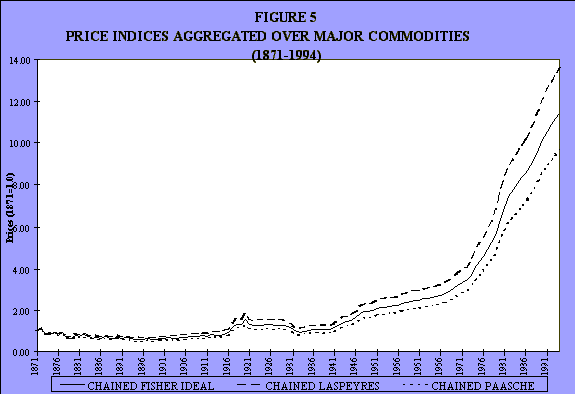
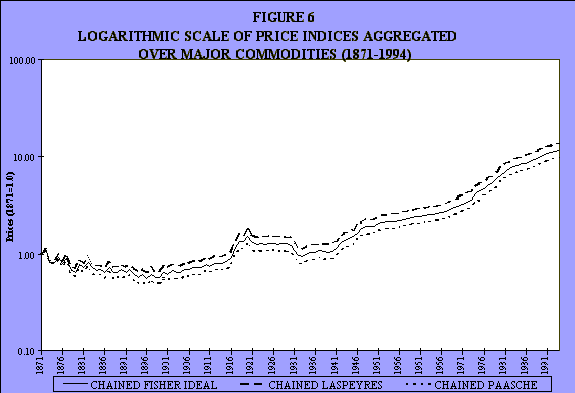
They then aggregated it using three different methods of aggregation: a chained Fisher ideal, a Laspeyres chained, and a Paasche chained (see Figures 5 and 6). As you would expect, the Fisher ideal is in between, the Laspeyres is higher, the Paasche is lower, just as one would expect, given the usual views on the subject.
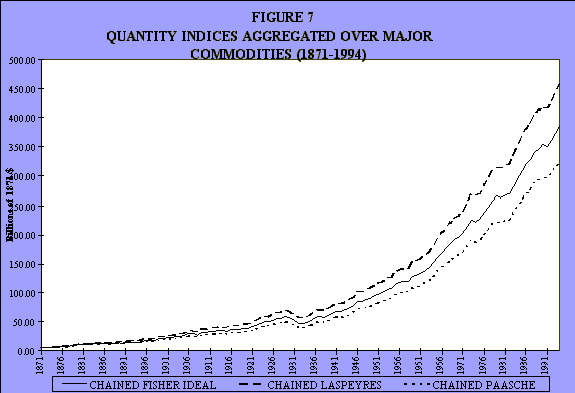
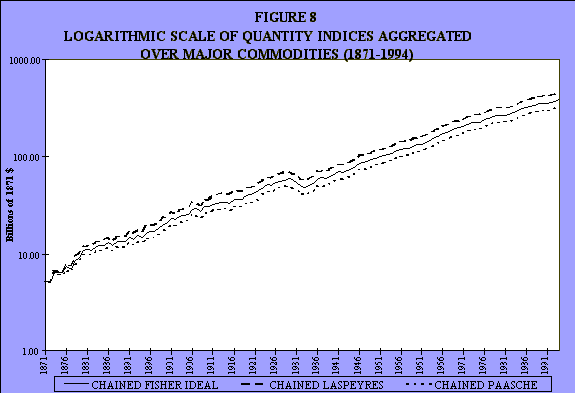
That's the quantity data (see Figure 7). They then changed that to semilogarithmic scale (see Figure 8). It's considerably less dramatic. It tends to support the view that one hears very frequently: the difference between the different index numbers when chained over very long periods of time sometimes is not as great as one might have expected. Some economists think it will explode. It seems like it's not quite as big of a deal as one might think. This is over 100 years. It has to do with volatility. The trend creates a cumulative bias, but volatility is another story.
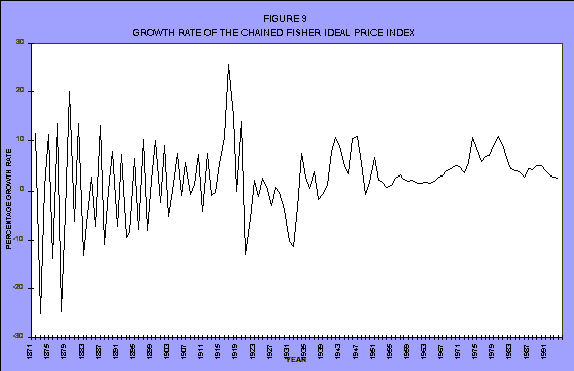
This is the growth rate of the chained Fisher ideal price index (see Figure 9). This is exactly what Romer's been talking about--very high volatility turning into substantially lower volatility.
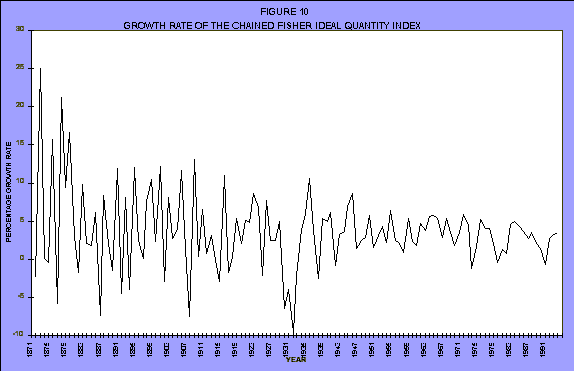
This is the corresponding quantity index--the same thing again--you can see what's happening with volatility (see Figure 10).
So I guess the point I want to make is that it would be useful to researchers if our concerns were perhaps given a bit higher priority. Right now the budget deficit and many other highly political matters that are hitting the BLS seem to be getting high priority. But there are other things that we might like to see provided from Washington that are not always that easy to acquire.
There are some other things I'd like to talk
about that are related to this. But because of the time restraints
I will refrain from saying more. If there's time later I may talk
about something else that's connected with this.
Triplett: Thank you very much. That latter comment about inviting people to do research on the subject actually reminded me of a comment made by George Stigler, who I referred to earlier, the chairman of the Stigler Committee. When asked by a Congressman something--I don't know what the question was, but I remember the answer, and it went something like the following. If you ask economists about bias in the CPI, you will get statements, a very overwhelming majority, that it's biased upwards,but if you ask them where are the research numbers on which their opinions are based, it's a very small set of numbers. We certainly have a lot more numbers today than when George Stigler made those remarks, but it's still a very small set of numbers. So the invitation to do research on these issues, I think, is welcome by the profession.
Now the original reason for stealing some minutes from the panelists was the notion that we would have some time at the end for exchanges between the panelists, and also some time at the end for questions from the audience. There's a certain N-dimensional orthogonality among the remarks here, so I don't see any natural sort of collisions.
But let me ask each of the panelists if you would like to do one or all of three things, very briefly: (1) Respond to any remarks made by other panelists that you think need response to. Then I have a couple of questions of my own that I am interested in responses to. (2) David made the remark about the necessity of having an underlying question for which the CPI should be the answer. Does the panel agree that the underlying, unifying framework for the Consumer Price Index ought to be a cost-of-living index? (3) My third question is--budget is a constraint--time and budget and knowledge are all constraints--so I would ask the panelists--this is a session on improving the CPI--where would you put priorities for work on the CPI?
And let me start with the same order we had before. Bob Gordon.
Gordon: To answer the first question, while I join many others in endorsing a cost-of-living definition for the CPI, I want to express some humility with the arbitrary choices that one must make in deciding where to stop in going from a price index of goods and services to a measure of the total social set of indicators of well being. An economist and a very perceptive critic of some of the critics of the CPI, Dean Baker, has come up with a long litany of things that one would need to take into account about diminished sense of security, increased crime, the consequences of low density suburbs requiring everybody to have two or three cars, and in general, the fact that people who don't have particular modern items like automobiles or telephones are much worse off today than people without those items 50 or 100 years ago when society was organized so that they were not necessities. So that the cost of living has a sort of really broad definition in economics, and implementing that does require some fairly arbitrary decisions about where to stop.
We tend to look for all those goods, in terms of new products, that have added to consumer welfare without really going through the list of bads that may have detracted from consumer welfare. Not everything environmental is bad, and we know that the air is cleaner--maybe not today in Chicago, but most days--than it was 30 years ago when the typical fuel burned was coal, and we know in London it is vastly cleaner almost every day than it was 50 years ago. So some environmental things have gotten better, and some environmental things have gotten worse.
On the issue of resources for the BLS, a totally different topic, I tend to be a skeptic, thinking that it's possible to do a different sort of job with different priorities within the BLS for approximately the same total budget. Katharine doesn't like to hear these things, but I've always felt that there was too much investment in collecting the price of bananas 100 different times, and too little investment in those tricky and difficult modern items, where a somewhat larger research department could make item by item comparisons or might hire consumer unions to do so, and make substantially more progress, have more bang for the buck, at the margin.
I know that our presentation today from the gentleman at my right heralded the modern new world of scanner data and the potential for a new concept for the CPI, at least for the subset of items which are swept through scanners at checkouts, and I've talked to Mr. Hawkes, who's in the audience, who until recently was with the Nielsen Company, about the feasibility of a scanner-based CPI for large parts of consumer goods--not necessarily services--and it does appear as if it might be feasible to replace whole hunks of the CPI field agent operation with a centralized computer reading and digesting scanner quantity and price data with up-to-the-minute weights for a fraction of the cost of collecting, say, food and apparel and some household items. So I think there's a lot of potential for reorienting the existing budget to focus on the problem areas, the feasibility of doing two or three different indexes instead of just one, without having additional resources
Triplett: Other panelists want to try one or more of those three questions. Bill?
Barnett: As I did before, I want to drift way off this subject in a way that is connected, but not the same thing.
Does the BLS and the Commission need expertise that, say, Congressmen and Senators do not have, and that lobbyists do not have? I wish to argue that from the standpoint of a researcher and the research community, that not only is there a need for expertise of a very high level, but I would argue there is a need for expertise of an even higher level than many of the professionals think.
To see that, I would refer people to an old source, the book by Fisher and Shell (1972). If you look at the Fisher and Shell book on index numbers, you will find that index number theory is even more fraught with difficult theoretical problems than many statisticians or economists wish to admit.
This is a very deep, difficult subject. For example, suppose we wish to look at a CPI price index, its dual quantity index, and somehow we want to put this into an economic model, so there is a price and a quantity on the demand side and a price and a quantity on the supply side. Suppose that all markets at the disaggregated level are cleared, so we're at complete general equilibrium--the economist's way of saying this. Suppose that there is a regulatory wedge in every market all the time. It means that on the demand side, the taxes that people pay are not exactly the same as the taxes paid on the supply side. Sales taxes, income taxes are not the same for firms as for consumers, etc. On the two sides of the market there's a different kind of taxation that goes on. Fisher and Shell (1972) proved that the quantity aggregates on the demand and supply side are not equal, even if they're equal at the disaggregated level. So all markets can be cleared at the disaggregated level, and at the macro level they're not cleared. In macroeconomics people like to think that demand and supply should be equal at the macro level if they are equal at the micro level. Not true.
Under non-homotheticity, even worse. It's then not true in terms of Malmquist and distance functions, which are the most reputable index numbers in the non-homothetic case, even if there is no regulatory wedge. What I'm suggesting is that index number theory is a difficult, deep subject. It's a subject for professionals, not for lobbyists and people like that. This is something that should be in the hands of people who understand these very difficult questions, because it's very difficult stuff.
It was stated by David Wilcox that there should be more than one index number. That's absolutely true. The question then is, how can we get this done in a way that, perhaps to a greater degree, is in the interest of the research community, not just the people with political power, or professional lobbyists, etc.
I think that's a very difficult question. Many people feel that there should be a central statistical bureau. This is common in many other countries; it's common in Canada. It makes me very nervous.
If I can have a couple of minutes to digress even further off of this, I would like to provide an illustration of why maybe the opposite is better. Maybe more decentralization and less centralization is better. The illustration I would like to suggest is the Federal Reserve system. The Federal Reserve system is uniquely decentralized. Not only is there the Federal Reserve Board in Washington, but there are regional banks that are very close to researchers, that have close ties with researcher in universities in their districts and are frequently very responsive to requests for data for their research, even when the Federal Reserve Board in Washington, where I was for eight years, sometimes is not. It's the decentralization that provides greater interchange.
Now, Katharine Abraham mentioned the existence of research databases--this is a very positive thing. But again, local representation of the sort that we have in the Federal Reserve system makes it even easier.
The illustration I'd like to provide is, in fact, not a CPI illustration, but I've only got about three transparencies to show you. This is very quick. But I wish to suggest that the effect can be very dramatic when there is closer connection between researchers and local representatives of data production agencies, rather than the distance that we presently have with most of the researchers in Washington, DC.
Triplett: While he's setting up, I should note that Ivan Fellegi, who's head of the centralized statistical agency in Canada, is in the audience, and has recently written an excellent paper on the properties of a fine statistical system, which I would commend to all of you if you want to pursue, though this is not the topic of this session.
Barnett: This is going to get even further off the topic of the session. But I think it's worth keeping these things in mind when people talk about things like further centralization of data production to a single data producing agency.
What I want to talk about has to do with the city of Chicago and some of the most famous researchers here in the city of Chicago. This displayed transparency is of a recent working paper that comes from the Federal Reserve Board staff. You can see this is very recent--it's the latest data on the monetary aggregate, M2. That's what you would find in this working paper that came from the Federal Reserve Board in Washington recently. You see back around here, in 1982, there was supposedly a gigantic spike in the money supply. Around this time, in this area of Chicago, there were two very famous macroeconomists. One, Bob Gordon, did not get suckered by this. There was another one, a very famous macroeconomist by the name of Milton Friedman. Milton Friedman, the person whose name is attached to monetarism, on the date September 26, 1983, published an article in Newsweek saying that there was a giant spike in the money supply. Therefore there was going to have to be a giant surge in inflation, which would then be followed by an overreaction by the Federal Reserve and a big recession.
He was, of course, wrong, and the monetarists have never recovered. But, of course, if the spike was there, he should have been right. All forms of economics, even under the most unusual views of money, say a big surge in money growth means inflation will follow. So it looked like Friedman had a very good point at the time.
What's been overlooked is that on the exact same day, September 26, 1983, in another magazine, in Forbes magazine, I was quoted saying the exact opposite, that there had been no such spike. The Federal Reserve Board apparently still thinks there had been. Well at Washington University, St. Louis, we're closer to the Federal Reserve Bank of St. Louis. It is about to release much better monetary aggregates based upon the Törnqvist index. It shows that that spike didn't exist, as is especially evident in Törnqvist L. I was aware of it when I granted that interview to Forbes, and obviously I was right.
Well if there hadn't been this decentralization of the system, we would still only be seeing the Federal Reserve Board's big spike, which is terrifically misleading, and obviously destroys macroeconomics if you believe the Federal Reserve Board's official simple sum monetary aggregates. But the spike didn't happen. It was due to regulatory changes affecting money market deposit accounts that were brought in with too high a weight, etc. I want to suggest that from the standpoint of research, this really ruined the careers of many monetarists. These data issues are big time, very big time. That's all I wish to say.
Wilcox: On the issue of whether the cost of living index should be taken as the intellectual benchmark for the Consumer Price Index, I want to cast an enthusiastic vote in the affirmative. In doing so, of course, I know that I am associating myself with a view that Jack Triplett expressed 15 years ago, as I noted earlier.
I also want to associate myself with Bob Gordon's comments to the effect that humility is very appropriate in this case. There are some very difficult issues to be resolved if we are to make the Consumer Price Index hew more closely to the concept of the cost of living. But absent some conceptual framework such as the theory of the cost of living, we really have no credible method for judging right from wrong, and better from not-so-good. Indeed, the absence of a clearly specified intellectual framework results in a lot of misapprehension among users about just what the Consumer Price Index represents.
As for the priorities of the Bureau of Labor Statistics, my co-author, Matthew Shapiro, recently used a wonderful metaphor. He talked about ìlow-hanging fruit,î and suggested that the first priority of the Bureau of Labor Statistics ought to be to pick the low-hanging fruit--that is, to follow the obvious principle of making the changes that will yield the biggest bang for the buck, and that are within our technical reach. Among these, my personal favorite would be to move the Consumer Price Index away from a fixed market basket concept. Not coincidentally, this would be consistent with a move toward a more faithful adherence to a cost-of-living concept as the intellectual motivation for the Consumer Price Index.
Lastly, I'm going to differ a little bit with Bill Barnett's comments just now, and endorse an idea that was mentioned by Kirk Wolter--namely, to collect prices, quantities, and expenditures all at the same outlets at the same time. In fact, Iíd like to propose an even more ambitious objective: I'd like to see surveys of retail establishments collect not only prices, quantities, and expenditures, but also employment, compensation, and inventories. This would require real coordination between the Bureau of Labor Statistics and the Census Bureau in drawing a coherent, unified sample. But such an undertaking could produce fundamental new insights into the dynamics of the retail sector--a sector that has received much less research attention than it deserves, partly for lack of really useful data. In addition, a radical transformation along these lines of the data-collection process could hold the prospect of reducing respondent burden for the business sector as a whole, even if concentrating it on a smaller number of business establishments. But perhaps that concentration could be dealt with by rotating the sample more frequently, or, conceivably, even compensating participants in the sample.
As for some of the questions that Commissioner Abraham raised, it seems to me that, indeed, more resources probably should be part of the picture. My sense is that Congress is becoming increasingly aware that the payoff to a sensible program of investment in economic statistics could be very high.
Wolter: I endorse the concept of coordinating the samples used by the Census Bureau and the Bureau of Labor Statistics. This is a great idea, although not a new one. In the context of the CPI, I think we can and should talk about realistically combining the functions of the Consumer Expenditure Survey, the POPS survey, and the monthly pricing survey into one scanning-based survey. I think all purchases in the country could be thought of as being partitioned into product-stratum by store-type by demographics-of-the-purchaser by area cells. And I think we could look at those cells and carefully start phasing in scanning data wherever it's cheap and accurate and made sense to do so. And I think that could happen, at least in theory, at a very early date. So that's one of the directions I would go in. And by collecting prices, quantities, and so on, from the same unit (household or store) at the same point in time, I think we blow away this entire issue of formula bias.
Let me just say that the sample sizes are potentially enormous. Ultimately, for example, if we had 10,000 stores reporting 10,000 items per week, that's 100 million price quotes per week. And that allows enormous opportunities for alternative indexes, or alternative time periods, or indexes for different store types, or for different purchaser demographics, and should allow for rich analyses of substitution between stores or between items.
Abraham: Iíd like to respond quickly to some of the other panelistsí ideas regarding different approaches the BLS might take to producing the CPI.
Bob Gordon talked about the number of prices the Bureau collects for bananas. I would note that there is an optimization algorithm behind the allocation of CPI price quotations to different item categories. The algorithm underlying the current sample allocation was designed to minimize the variance of the six-month change in the estimated index, subject to our budget constraint and to the constraint I discussed earlier that all of the item-area cells on which the index rests get filled in. We have a large number of price quotations for bananas because banana prices are both volatile and very cheap to collect. Having said this, Iíd quickly add that we are certainly open to rethinking what weíre doing if a better approach is proposed.
There is a lot of interest in the contribution that scanner data can make to improving the CPI. Bureau staff already are engaged in research using scanner data that may help us to answer questions about, for example, substitution across items with item categories. Scanner data also ultimately might substitute for some of the information currently collected as part of our Consumer Expenditure Survey and Point of Purchase Survey. There are, however, some practical issues to be considered regarding the potential use of scanner data to construct the monthly CPI.
First, the coverage of scanner data is very partial. Scanner data are available for perhaps 20 percent of the item category weight in the CPI, and even for those items certain types of outlets are excluded. Even if we were to move towards using scanner data in the CPI production process, weíd be talking about a hybrid process for the forseeable future, with whatever operational complications that would entail. Second, I do not know whether the companies that collect scanner data could transmit it to us in time for incorporation in the production of the CPI. Third, I must say that I would have some grave reservations about relying on data from any single private source to produce the CPI. The scanner data companies have many customers; their products and processes have not been and would not be designed principally for the purpose of meeting the needs of the BLS. If the company that we were dealing with decided to change its collection methods or change the way it was reporting data -- or, even worse, were to go out of business -- our ability to produce a major economic indicator in a consistent fashion on an on-going basis would be jeopardized. Iím not sure this would be a risk I would want to take.
There are, of course, some even more radical things we might think about doing. I will confess to being particularly intrigued by Kirk Wolterís notion of making use in some way of household-based scanner data that might be more comprehensive in coverage than the store-based scanner data. Iím also intrigued by David Wilcoxís notion of seeking ways to combine some of the various separate establishment surveys that the various statistical agencies currently conduct to collect different sorts of information. There are some obvious reasons to be cautious about moving in this direction. A single massive survey likely would impose an unacceptably large burden on establishments, especially smaller establishments, selected for participation. Moreover, the people at a firm who are knowledgeable about one kind of information may not be knowledgeable about other kinds of information. But I do think that we should be looking for survey integration opportunities that might reduce respondent burden and simultaneously increase the value of the information we collect.
Triplett: Well we have a little time for questions from the floor.
I must say I want to weigh in on this issue of prices for bananas. That may seem like not the most vital issue in the CPI. But you know, one of the problems, I think, with the algorithm that the BLS used in the last revision of the CPI, was that the algorithm that drew the sample was based on the implicit, almost explicit, but certainly implicit, assumption that the only thing that mattered was the overall CPI. I think there are many cases in which the individual products of the CPI are vital information for a lot of economic analysis, and I guess maybe putting some resources into those non-banana items would be to recognize that the individual prices are also important for analysis. And some of those other prices have great interest in their own right. So I'd like to see a modification of the algorithm that optimizes across the sample, so that you've got an objective function that includes the price information for basic components as well as the overall CPI.
Now, we've got a little time left for questions from the floor. I think what I'll have to ask you to do is to stand up and speak loudly so the panel can hear, and if the audience can't hear, maybe I'll try to relay the question back. Start right up here.
Q: I'd like to pose and focus some attention on what I think is a very fundamental question, how do we restore public confidence in the CPI? And I'd like to suggest that no matter how deep, how difficult the response, that it be phrased in a context that the general public can understand--not a statistician, not the economist not the researchers, not even the Congress--but the general public can understand.
Triplett: Let me rephrase that question. It's a question of how can we restore the public confidence in the CPI. And I was thinking about that myself in this discussion. There's all this praise among the professionals for the professionals in the BLS, and I share that feeling. I think that the professionals I know in the BLS are to be praised also. But the nature of this panel discussion this morning isn't very consistent with what we sometimes read in the newspapers.
Well, I think it's a good question. I think we all need to think about that question. It is a difficult question and it also gets at what Bill Barnett was saying, that sometimes you don't always have the answers for hard questions handled by researchers. And unfortunately, when you don't have all the answers, sometimes that's news, and it's not positive news.
I guess we don't have an answer for that question. But we all recognize that that's really a vital question.
Other questions from the audience?
Q: My name is de Michelis. I am speaking as a representative of the European Statistical Office. I know this is a controversial issue and I am not very familiar with the American CPI. I just wanted to inform the audience that there is a very major project going on in the European Union at present in the harmonization of the CPIs of the member states. For the monetary union effective in the year 1999, we have built up a harmonized CPI for all the member states, and there is a major project going on, in which all these problems have been tackled by very high level specialists, not only from the European Union, but also with the support of people coming from the United States and Canada, we have had consultation on methodology.
Our new harmonized CPI will be coming forth in 1997, and the methodology will be published at the beginning of 1997. We had last year in Florence a seminar, with the participation of very high level people coming from universities, statistical offices, and governments. And we are going to publish in the next two weeks, I hope, the book on the specific recommendations on harmonization of price indexes.
Triplett: Thank you Mr. Alberto de Michelis, who has under him a number statistical programs in Eurostat including national accounts, price statistics, and some other interesting issues. Thank you for your comment, and I know from talking with European statistical agencies that the items in the newspapers in the U.S. about the U.S. CPI are of great concern in Europe because there's a sense in which people transfer what's said about the CPI in the U.S. to the CPIs of other countries.
I think I saw another hand.
Q: In the spirit of the defense of the BLS employees, I'd just like to refer Professor Barnett to the record of Chicago economists in winning Nobel prizes over the last ten or twenty years.
Triplett: Other questions from the floor.
Q: This is directed to Commissioner Abraham. You mentioned that the medical index was being revised. Do you have an experimental index now that you can use to compare and find the effects of the change?
Abraham: We donít have an experimental measure available. Weíve not priced out whole hospital bills in the CPI in the past, so we donít have the information weíd need to produce an experimental measure.
The change that weíre making moves the CPI medical care indexes towards being more like the Producer Price Index (PPI) measures in the way theyíre put together. It may be that you could glean something from comparing the two, though there are differences in the scope of coverage between them. I would refer you to the description of the change weíre making in the medical components of the CPI in the handout Iíve distributed and also to the article in this monthís Monthly Labor Review that describes the Producer Price medical care indexes (Catron and Murphy, 1996).
Triplett: One last question. Charles Waite.
Q: I have the impression that what the Congress is after from the Boskin Commission is a magic number, a magic number by which the gang of five, or the dream team, will come up with, which will say what the annual overstatement of the CPI will be deemed to be so that then the Congress can possibly adjust legislation for Social Security and other matters. Is it the intention, Bob, that such a magic number will emerge in December?
Triplett: It isn't magic. It's a well considered professional number, right?
Gordon: I'm very sensitive about this issue because of a totally different topic, and that is the concept of the natural rate of unemployment, the unemployment rate that's consistent with steady inflation, a very important issue for monetary policy and macroeconomics. It has recently been claimed by some eminent econometricians that one cannot bound this magic number in a range narrower than 5 to 8 percent, which if true it would be totally useless for monetary policy. And I find it very easy to reject that statistical conclusion, because it makes no sense economically.
Now because, perhaps, of that background, I really resist the alternative for our Commission of coming up with a range. Because if we come up with a range it's going to be very likely that people will take the midpoint of the range as the point estimate anyway. So I think we'd better do the best job that we can with the various pieces. And while bowing in the direction of humility, I predict we'll come up with a point estimate, just as we did in the initial interim report.
Triplett: But what is it?
Gordon: December 1st.
Triplett:
Thank you very much.
REFERENCES
Catron, B., and Murphy, B. (1996), "Hospital Price Inflation: What Does the New PPI Tell Us?" Monthly Labor Review, 119, no. 7, 24-31.
Fisher, F.M., and Shell, K. (1972), The
Economic Theory of Price Indexes, New York: Academic Press.